前言
DBA 可能是经常被其它团队依赖的一种角色、团队,因此他们也会有着很长的等待队列,也经常是事故救火中的英雄和常客。DevOps 强调用跨角色的学习和培训来解决这种依赖,也就是 DevOps 工作三步法的第三步,学习与持续改进。 本文写给所有的应用开发者,希望大家能多学习一些 DBA 知识,减少对专家 DBA 的依赖,加速你们的业务的交付,消除由于等待而造成的浪费。
本文转载自:https://hakibenita.com/sql-tricks-application-dba
以下是正文原文:
当我开始我的开发生涯时,我的第一份工作是DBA。那时,在AWS RDS、Azure、Google Cloud和其余云服务之前,有两种类型的DBA。
基础设施 DBA 负责建立数据库配置存储,并负责备份和复制。设置好数据库后,基础架构DBA会时不时地冒出来做一些 “实例调整”,比如调整缓存的大小。
应用 DBA 从基础架构DBA那里得到了一个干净的数据库,并负责模式设计:创建表、索引、约束和调优SQL。应用DBA也是实现ETL流程和数据迁移的人。在使用存储过程的团队中,应用DBA也会维护这些存储过程。
应用DBA通常是开发团队的一部分。他们会拥有深厚的领域知识,所以通常他们只会在一两个项目上工作。基础架构DBA通常是某个IT团队的一部分,他们会同时在多个项目上工作。
我是一名应用DBA 我从来没有任何欲望去摆弄备份或调整存储(我相信这很迷人!)。直到今天,我都喜欢说自己是一个懂得开发应用的DBA,而不是一个懂得数据库的开发者。
在本文中,我将分享我一路走来收集到的一些关于数据库开发的非浅显技巧。

Be that guy…Image by CommitStrip
只更新需要更新的内容
UPDATE是一个相对昂贵的操作。为了加快UPDATE命令的速度,最好确保只更新需要更新的内容。
以这个查询为例,它对电子邮件列进行了标准化处理。
1
2
3
| db=# UPDATE users SET email = lower(email);
UPDATE 1010000
Time: 1583.935 ms (00:01.584)
|
看起来很无辜吧,查询更新了1010,000个用户的邮箱。但是,真的需要更新所有的行吗?
1
2
3
4
| db=# UPDATE users SET email = lower(email)
db-# WHERE email != lower(email);
UPDATE 10000
Time: 299.470 ms
|
只需要更新10000行。通过减少受影响的行数,执行时间从1.5秒降到了不到300ms。更新的行数少了,也节省了后期的数据库维护工作。

这种类型的大更新在数据迁移脚本中非常常见。所以下次写迁移脚本时,一定要只更新需要更新的内容。
在批量加载过程中禁用约束和索引
约束是关系型数据库的重要组成部分:它们能保持数据的一致性和可靠性。不过它们的好处是有代价的,在加载或更新大量行时最明显。
为了演示,为一个存储设置一个小模式。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| DROP TABLE IF EXISTS product CASCADE;
CREATE TABLE product (
id serial PRIMARY KEY,
name TEXT NOT NULL,
price INT NOT NULL
);
INSERT INTO product (name, price)
SELECT random()::text, (random() * 1000)::int
FROM generate_series(0, 10000);
DROP TABLE IF EXISTS customer CASCADE;
CREATE TABLE customer (
id serial PRIMARY KEY,
name TEXT NOT NULL
);
INSERT INTO customer (name)
SELECT random()::text
FROM generate_series(0, 100000);
DROP TABLE IF EXISTS sale;
CREATE TABLE sale (
id serial PRIMARY KEY,
created timestamptz NOT NULL,
product_id int NOT NULL,
customer_id int NOT NULL
);
|
模式定义了不同类型的约束,如 “非空 “和唯一约束。
要设置一个基线,首先要向销售表添加外键,然后将一些数据加载到表中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| db=# ALTER TABLE sale ADD CONSTRAINT sale_product_fk
db-# FOREIGN KEY (product_id) REFERENCES product(id);
ALTER TABLE
Time: 18.413 ms
db=# ALTER TABLE sale ADD CONSTRAINT sale_customer_fk
db-# FOREIGN KEY (customer_id) REFERENCES customer(id);
ALTER TABLE
Time: 5.464 ms
db=# CREATE INDEX sale_created_ix ON sale(created);
CREATE INDEX
Time: 12.605 ms
db=# INSERT INTO SALE (created, product_id, customer_id)
db-# SELECT
db-# now() - interval '1 hour' * random() * 1000,
db-# (random() * 10000)::int + 1,
db-# (random() * 100000)::int + 1
db-# FROM generate_series(1, 1000000);
INSERT 0 1000000
Time: 15410.234 ms (00:15.410)
|
定义约束和索引后,将100万行加载到表中,耗时约15.4s。
接下来,尝试先将数据加载到表中,然后才添加约束和索引。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| db=# INSERT INTO SALE (created, product_id, customer_id)
db-# SELECT
db-# now() - interval '1 hour' * random() * 1000,
db-# (random() * 10000)::int + 1,
db-# (random() * 100000)::int + 1
db-# FROM generate_series(1, 1000000);
INSERT 0 1000000
Time: 2277.824 ms (00:02.278)
db=# ALTER TABLE sale ADD CONSTRAINT sale_product_fk
db-# FOREIGN KEY (product_id) REFERENCES product(id);
ALTER TABLE
Time: 169.193 ms
db=# ALTER TABLE sale ADD CONSTRAINT sale_customer_fk
db-# FOREIGN KEY (customer_id) REFERENCES customer(id);
ALTER TABLE
Time: 185.633 ms
db=# CREATE INDEX sale_created_ix ON sale(created);
CREATE INDEX
Time: 484.244 ms
|
将数据加载到没有索引和约束的表中,速度快了很多,2.27s,而之前是15.4s。在数据加载到表中后创建索引和约束花了一点时间,但总体上整个过程快了很多,3.1s,而之前是15.4s。
遗憾的是,对于索引,PostgreSQL并没有提供一个简单的方法,除了放弃和重新创建索引。在其他数据库中,如Oracle,你可以禁用和启用索引,而不必重新创建索引。
中间数据中使用 UNLOGGED 的表
当你修改PostgreSQL中的数据时,修改的内容会被写入提前写日志(WAL)。WAL用于维护完整性,在恢复期间快速推进数据库,并维护复制。
写入WAL是经常需要的,但在某些情况下,你可能愿意放弃它的一些用途来使事情变得更快。一个例子是中间表。
中间表是一次性的表,它存储了用于实现某些过程的临时数据。例如,ETL过程中一个非常常见的模式是将数据从CSV文件加载到中间表,清理数据,然后加载到目标表。在这种用例中,中间表是一次性的,在备份或复制中没有用处。
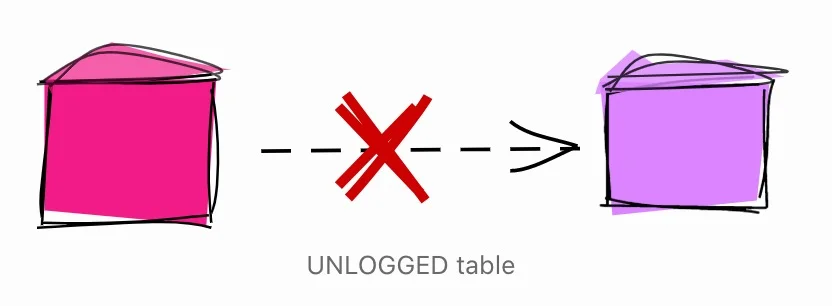
在灾难发生时不需要恢复的中间表,以及在副本中不需要的中间表,可以设置为 UNLOGGED。
1
| CREATE UNLOGGED TABLE staging_table ( /* table definition */ );
|
**注意:**在使用UNLOGGED之前,请务必了解其全部含义。
使用 WITH 和 RETURNING 实施完成的流程
假设你有一个用户表,你发现表中有一些重复的内容。
表的设置:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| CREATE TABLE users (
id SERIAL PRIMARY KEY,
email TEXT UNIQUE
);
CREATE TABLE orders (
id SERIAL PRIMARY KEY,
user_id INT,
CONSTRAINT orders_user_fk
FOREIGN KEY (user_id)
REFERENCES USERS(id)
);
INSERT INTO users (email) VALUES
('foo@bar.baz'),
('me@hakibenita.com'),
('ME@hakibenita.com');
INSERT INTO orders (user_id) VALUES
(1),
(1),
(2),
(3),
(3);
|
表的内容:
1
2
3
4
5
6
7
8
9
10
| db=# SELECT u.id, u.email, o.id as order_id
FROM orders o JOIN users u ON o.user_id = u.id;
id | email | order_id
----+-------------------+----------
1 | foo@bar.baz | 1
1 | foo@bar.baz | 2
2 | me@hakibenita.com | 3
3 | ME@hakibenita.com | 4
3 | ME@hakibenita.com | 5
|
用户haki benita注册了两次,一次是用邮箱ME@hakibenita.com,另一次是用me@hakibenita.com。由于我们在将邮件插入表中时没有将其规范化,现在我们必须处理重复的问题。
为了合并重复的用户,我们要。
- 通过小写的电子邮件来识别重复的用户。
- 更新订单以引用其中一个重复的用户。
- 从用户表中删除重复的用户
整合重复用户的一种方法是使用中间表。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| db=# CREATE UNLOGGED TABLE duplicate_users AS
db-# SELECT
db-# lower(email) AS normalized_email,
db-# min(id) AS convert_to_user,
db-# array_remove(ARRAY_AGG(id), min(id)) as convert_from_users
db-# FROM
db-# users
db-# GROUP BY
db-# normalized_email
db-# HAVING
db-# count(*) > 1;
CREATE TABLE
db=# SELECT * FROM duplicate_users;
normalized_email | convert_to_user | convert_from_users
-------------------+-----------------+--------------------
me@hakibenita.com | 2 | {3}
|
中间表持有重复用户的映射。对于每一个使用相同的标准化电子邮件地址出现不止一次的用户,我们定义最小ID的用户作为我们将所有重复用户转换为的用户。其他用户被保存在一个数组列中,这些用户的所有引用都将被更新。
利用中间表,我们更新订单表中重复用户的引用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| db=# UPDATE
db-# orders o
db-# SET
db-# user_id = du.convert_to_user
db-# FROM
db-# duplicate_users du
db-# WHERE
db-# o.user_id = ANY(du.convert_from_users);
UPDATE 2
Now that there are no more references, we can safely delete the duplicate users from the users table:
db=# DELETE FROM
db-# users
db-# WHERE
db-# id IN (
db(# SELECT unnest(convert_from_users)
db(# FROM duplicate_users
db(# );
DELETE 1
|
请注意,我们使用了函数 unnest 来 “转置 “数组,即把每个数组元素变成一行。
这就是结果:
1
2
3
4
5
6
7
8
9
| db=# SELECT u.id, u.email, o.id as order_id
db-# FROM orders o JOIN users u ON o.user_id = u.id;
id | email | order_id
----+-------------------+----------
1 | foo@bar.baz | 1
1 | foo@bar.baz | 2
2 | me@hakibenita.com | 3
2 | me@hakibenita.com | 4
2 | me@hakibenita.com | 5
|
很好,用户3(ME@hakibenita.com)的所有出现都转换为用户2(me@hakibenita.com)。
我们还可以验证重复的用户是否从用户表中被删除。
1
2
3
4
5
6
| db=# SELECT * FROM users;
id | email
----+-------------------
1 | foo@bar.baz
2 | me@hakibenita.com
|
现在我们可以摆脱中间表了。
1
2
| db=# DROP TABLE duplicate_users;
DROP TABLE
|
这个很好,但是非常长,需要清理! 有没有更好的方法?
使用通用表表达式(CTE)
使用常见的表表达式,也就是所谓的WITH子句,我们只需要一条SQL语句就可以执行整个过程。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| WITH duplicate_users AS (
SELECT
min(id) AS convert_to_user,
array_remove(ARRAY_AGG(id), min(id)) as convert_from_users
FROM
users
GROUP BY
lower(email)
HAVING
count(*) > 1
),
update_orders_of_duplicate_users AS (
UPDATE
orders o
SET
user_id = du.convert_to_user
FROM
duplicate_users du
WHERE
o.user_id = ANY(du.convert_from_users)
)
DELETE FROM
users
WHERE
id IN (
SELECT
unnest(convert_from_users)
FROM
duplicate_users
);
|
我们不创建中间表,而是创建一个通用的表表达式,并多次重复使用。
从 CTE 返回结果
在WITH子句中执行DML的一个很好的特性是,你可以使用RETURNING关键字来返回数据。例如,让我们报告更新和删除的行数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| WITH duplicate_users AS (
SELECT
min(id) AS convert_to_user,
array_remove(ARRAY_AGG(id), min(id)) as convert_from_users
FROM
users
GROUP BY
lower(email)
HAVING
count(*) > 1
),
update_orders_of_duplicate_users AS (
UPDATE
orders o
SET
user_id = du.convert_to_user
FROM
duplicate_users du
WHERE
o.user_id = ANY(du.convert_from_users)
RETURNING o.id
),
delete_duplicate_user AS (
DELETE FROM
users
WHERE
id IN (
SELECT unnest(convert_from_users)
FROM duplicate_users
)
RETURNING id
)
SELECT
(SELECT count(*) FROM update_orders_of_duplicate_users) AS orders_updated,
(SELECT count(*) FROM delete_duplicate_user) AS users_deleted
;
|
这个结果是:
1
2
3
| orders_updated | users_deleted
----------------+---------------
2 | 1
|
这种方法的主要吸引力在于,整个过程是在一条命令中执行的,所以不需要管理一个事务,也不需要担心在过程失败时清理中间表。
**注意:**Reddit上的一位读者给我指出了在普通表表达式中执行DML的一个可能无法预测的行为。
WITH中的子语句相互之间以及与主查询同时执行。因此,当在WITH中使用数据修改语句时,指定的更新实际发生的顺序是不可预测的。
这意味着你不能依赖独立子语句的执行顺序。看来,当子语句之间存在依赖关系时,比如在上面的例子中,你可以依靠依赖的子语句在被使用之前执行。
避免在选择性低的列上使用索引
假设你有一个注册流程,用户用电子邮件地址注册。为了激活帐户,他们必须验证他们的电子邮件。你的表可以是这样的。
1
2
3
4
5
6
| db=# CREATE TABLE users (
db-# id serial,
db-# username text,
db-# activated boolean
db-#);
CREATE TABLE
|
你的大部分用户都是好公民,他们用有效的邮箱注册,并立即激活账号。让我们用用户数据来填充表格,其中大概有90%的用户被激活。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| db=# INSERT INTO users (username, activated)
db-# SELECT
db-# md5(random()::text) AS username,
db-# random() < 0.9 AS activated
db-# FROM
db-# generate_series(1, 1000000);
INSERT 0 1000000
db=# SELECT activated, count(*) FROM users GROUP BY activated;
activated | count
-----------+--------
f | 102567
t | 897433
db=# VACUUM ANALYZE users;
VACUUM
|
要查询已激活和未激活的用户,你可能会想在列激活上创建一个索引。
1
2
| db=# CREATE INDEX users_activated_ix ON users(activated);
CREATE INDEX
|
当你试图查询未激活的用户时,数据库正在使用索引。
1
2
3
4
5
6
7
| db=# EXPLAIN SELECT * FROM users WHERE NOT activated;
QUERY PLAN
--------------------------------------------------------------------------------------
Bitmap Heap Scan on users (cost=1923.32..11282.99 rows=102567 width=38)
Filter: (NOT activated)
-> Bitmap Index Scan on users_activated_ix (cost=0.00..1897.68 rows=102567 width=0)
Index Cond: (activated = false)
|
数据库估计,过滤后会有102567个,这大概是表的10%。这与我们填充的数据是一致的,所以数据库对数据的感觉很好。
但是,当你尝试查询激活用户时,你发现数据库决定不使用索引。
1
2
3
4
5
| db=# EXPLAIN SELECT * FROM users WHERE activated;
QUERY PLAN
---------------------------------------------------------------
Seq Scan on users (cost=0.00..18334.00 rows=897433 width=38)
Filter: activated
|
很多开发人员在数据库没有使用索引的时候,往往会感到困惑。解释为什么索引并不总是最好的选择的一种方法是:如果你必须读取整个表,你会使用索引吗?
答案可能是否定的,因为你为什么要这样做?从磁盘上读取是很昂贵的,你希望尽可能少地读取。例如,如果一个表是10MB,索引是1MB,要读取整个表,你就必须从磁盘上读取10MB。如果要使用索引来读取表,你就必须从磁盘上读取11MB。这是很浪费的。
有了这样的理解,我们来看看PostgreSQL对表的收集统计。
1
2
3
4
5
6
7
8
| db=# SELECT attname, n_distinct, most_common_vals, most_common_freqs
db-# FROM pg_stats
db-# WHERE tablename = 'users' AND attname='activated';
------------------+------------------------
attname | activated
n_distinct | 2
most_common_vals | {t,f}
most_common_freqs | {0.89743334,0.10256667}
|
当PostgreSQL分析该表时,发现激活的列有两个不同的值。most_common_vals列中的值t对应的是most_common_freqs列中的频率0.89743334,值f对应的是频率0.10256667。也就是说,经过分析,数据库估计表中89.74%是激活用户,其余10.26%是未激活用户。
通过这些统计,PostgreSQL决定,如果希望90%的行满足条件,最好扫描整个表。过了这个阈值,数据库可能会决定使用或不使用索引,这取决于很多因素,没有一个经验法则可以使用。
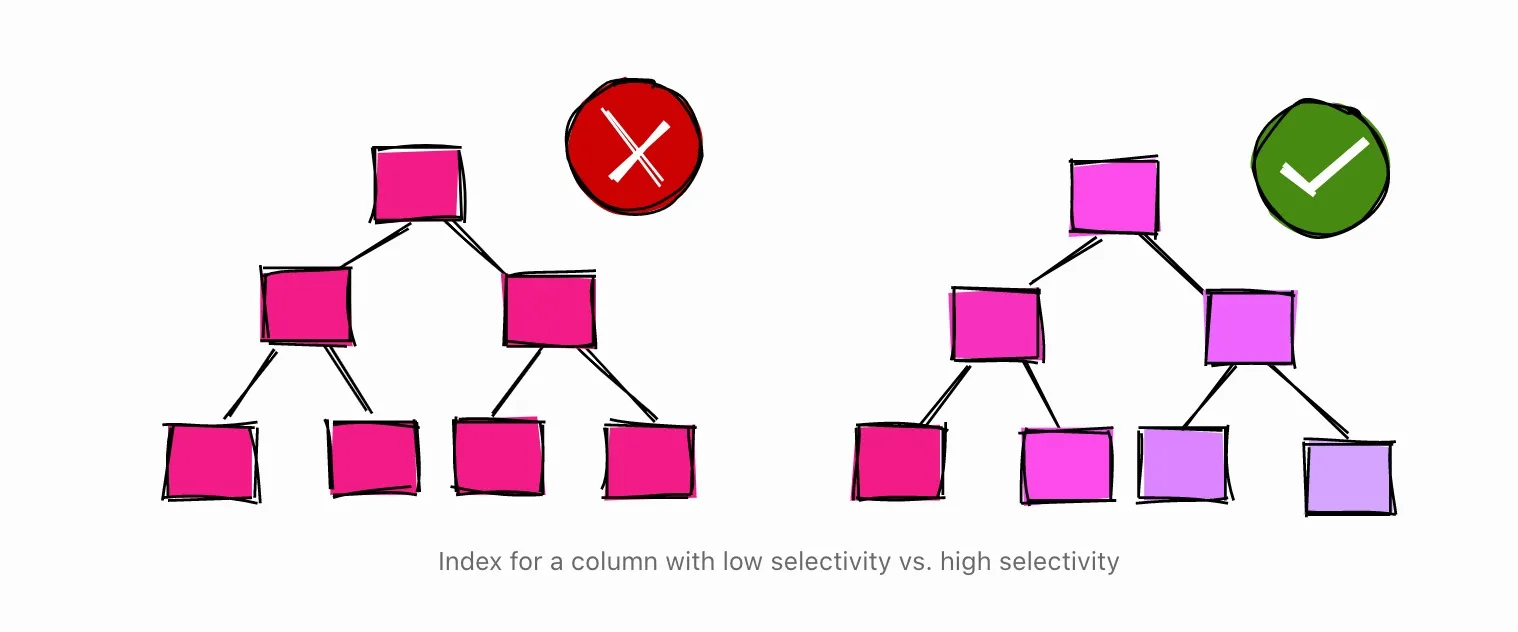
使用部分索引
在上一节中,我们在布尔值列上创建了一个索引,其中90%的值为真(激活用户)。当我们试图查询活跃用户时,数据库没有使用该索引。然而,当我们查询未激活的用户时,数据库却使用了该索引。
这就引出了下一个问题……如果数据库不打算使用索引来过滤活跃用户,那么我们为什么要首先使用索引呢?
在回答这个问题之前,我们先来看看激活列上的完整索引有多大重量。
1
2
3
4
5
| db=# \di+ users_activated_ix
Schema | Name | Type | Owner | Table | Size
--------+--------------------+-------+-------+-------+------
public | users_activated_ix | index | haki | users | 21 MB
|
索引是21MB。仅供参考,用户表是65MB。这意味着索引的重量约为表的32%。我们也知道~90%的索引可能不会被使用。
在PostgreSQL中,有一种方法可以只在表的一部分创建索引,使用所谓的部分索引。
1
2
3
| db=# CREATE INDEX users_unactivated_partial_ix ON users(id)
db-# WHERE not activated;
CREATE INDEX
|
使用WHERE子句,我们限制了索引所索引的行。首先让我们确认一下它是否有效。
1
2
3
4
| db=# EXPLAIN SELECT * FROM users WHERE not activated;
QUERY PLAN
------------------------------------------------------------------------------------------------
Index Scan using users_unactivated_partial_ix on users (cost=0.29..3493.60 rows=102567 width=38)
|
令人惊奇的是,数据库很聪明,它明白我们在查询中使用的谓词可以通过部分索引来满足。
使用部分索引还有一个好处。
1
2
3
4
5
| db=# \di+ users_unactivated_partial_ix
List of relations
Schema | Name | Type | Owner | Table | Size
--------+------------------------------+-------+-------+-------+---------
public | users_unactivated_partial_ix | index | haki | users | 2216 kB
|
部分索引仅重2.2MB。列上的全索引重达21MB。部分索引的大小正好是全索引的10%,这与表中非活跃用户的比例相匹配。
始终加载排序过的数据
这是我在代码评审中评论最多的事情之一。它不像其他提示那样直观,它对性能的影响很大。
比如说你有一个大的销售事实表。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| db=# CREATE TABLE sale_fact (id serial, username text, sold_at date);
CREATE TABLE
Every night, during some ETL process, you load data into the table:
db=# INSERT INTO sale_fact (username, sold_at)
db-# SELECT
db-# md5(random()::text) AS username,
db-# '2020-01-01'::date + (interval '1 day') * round(random() * 365 * 2) AS sold_at
db-# FROM
db-# generate_series(1, 100000);
INSERT 0 100000
db=# VACUUM ANALYZE sale_fact;
VACUUM
|
为了伪造一个加载过程,我们使用了随机数据。我们插入了10万行随机的用户名,销售日期从2020-01-01到未来两年。
该表主要用于制作汇总销售报表。大多数报表都是通过日期来过滤,得到特定时期的销售情况。为了加快范围扫描,你可以在sold_at上创建一个索引。
1
2
| db=# CREATE INDEX sale_fact_sold_at_ix ON sale_fact(sold_at);
CREATE INDEX
|
让我们看看一个查询的执行计划,以获取2020年6月的所有销售。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| db=# EXPLAIN (ANALYZE)
db-# SELECT *
db-# FROM sale_fact
db-# WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
-----------------------------------------------------------------------------------------------
Bitmap Heap Scan on sale_fact (cost=108.30..1107.69 rows=4293 width=41)
Recheck Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Heap Blocks: exact=927
-> Bitmap Index Scan on sale_fact_sold_at_ix (cost=0.00..107.22 rows=4293 width=0)
Index Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Planning Time: 0.191 ms
Execution Time: 5.906 ms
|
在执行了几次查询预热缓存后,时间稳定在约6ms。
Bitmap Scan
从执行计划来看,我们可以看到数据库使用了位图扫描。位图扫描的工作分为两个阶段。
- 位图索引扫描。浏览整个索引sale_fact_sold_at_ix 并映射所有包含相关记录的表页。
- 位图堆扫描:读取包含相关行的页面。读取包含相关行的页面,并在这些页面中找到满足条件的行。
页面可以包含多条记录。第一步使用索引来查找页面。第二步检查这些页面里面的行,因此执行计划中的 “Recheck Cond “操作。
这时,很多DBA和开发人员都会收工,继续进行下一个查询。BUT,有一个方法可以让这个查询变得更好。
Index Scan
为了让事情变得更好,我们会在加载数据的方式上做一个小小的改变。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| db=# TRUNCATE sale_fact;
TRUNCATE TABLE
db=# INSERT INTO sale_fact (username, sold_at)
db-# SELECT
db-# md5(random()::text) AS username,
db-# '2020-01-01'::date + (interval '1 day') * round(random() * 365 * 2) AS sold_at
db-# FROM
db-# generate_series(1, 100000)
db-# ORDER BY sold_at;
INSERT 0 100000
db=# VACUUM ANALYZE sale_fact;
VACUUM
|
这次,我们加载的数据是按sold_at排序的。
让我们看看现在完全相同的查询的执行计划是什么样子的。
1
2
3
4
5
6
7
8
9
10
11
| db=# EXPLAIN (ANALYZE)
db-# SELECT *
db-# FROM sale_fact
db-# WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
---------------------------------------------------------------------------------------------
Index Scan using sale_fact_sold_at_ix on sale_fact (cost=0.29..184.73 rows=4272 width=41)
Index Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Planning Time: 0.145 ms
Execution Time: 2.294 ms
|
在运行了几次查询后,我们得到了一个稳定在2.3ms的轮回时间。与之前的查询耗时约6ms相比,我们得到了约60%的稳定节省。
还有一点我们可以马上看到,这次数据库没有使用位图扫描,而是使用了 “常规 “索引扫描。为什么会这样呢?
Correlation
当数据库在分析一张表时,它会收集各种统计数据。其中一个统计是相关性。
物理行排序和逻辑列值排序之间的统计相关性。这个范围从-1到+1。当该值接近-1或+1时,由于减少了对磁盘的随机访问,估计对该列进行索引扫描会比接近零时更便宜。
正如官方文档所解释的那样,相关性衡量了特定列值在磁盘上的 “排序 “程度。
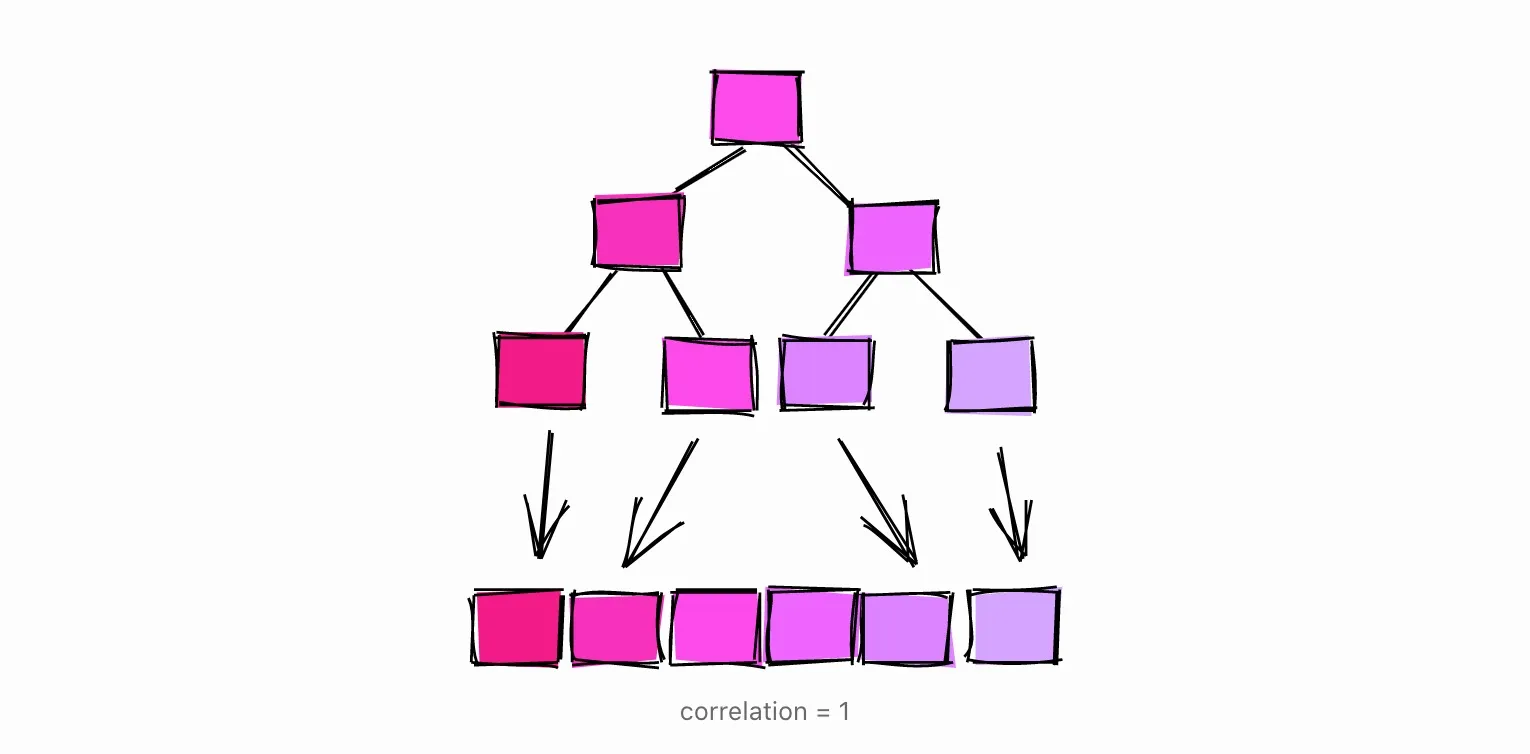
当相关性为1,或接近1时,意味着表中的页在磁盘上的存储顺序与表中的行大致相同。这其实是很常见的。例如,自动递增的ID通常会有接近1的相关性。跟踪行创建时间的日期和时间戳列通常也会有接近于1的相关性。
当相关性为-1时,表的页面相对于列的排序顺序是相反的。
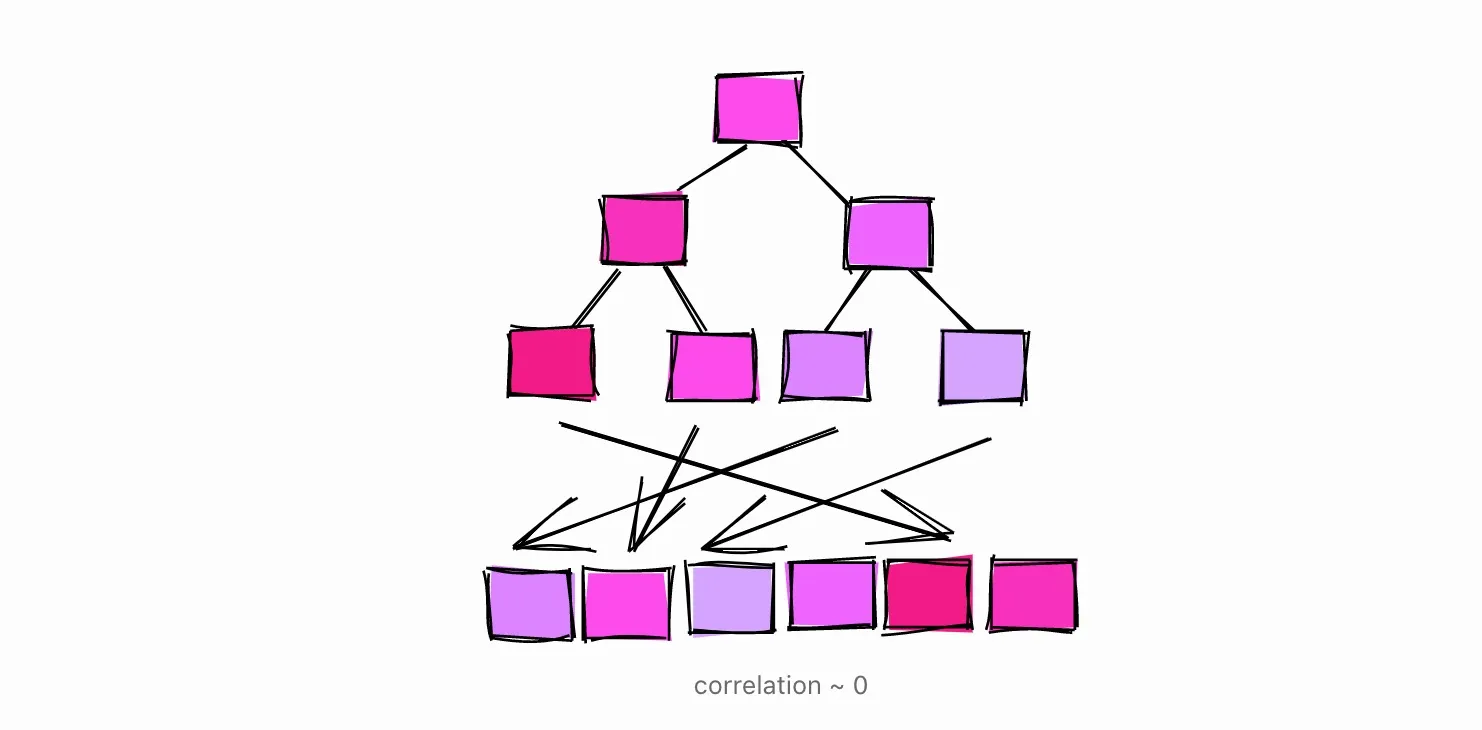
当相关性接近0时,意味着列中的值与表的页面存储方式没有相关性或相关性很小。
回到我们的sale_fact表,当我们将数据加载到表中时,没有先进行排序,这些就是相关性。
1
2
3
4
5
6
7
8
9
| db=# SELECT tablename, attname, correlation
db-# FROM pg_stats
db=# WHERE tablename = 'sale_fact';
tablename | attname | correlation
-----------+----------+--------------
sale | id | 1
sale | username | -0.005344716
sale | sold_at | -0.011389783
|
自动生成的列id的相关性为1,sold_at列的相关性很低:连续的值分散在整个表中。
当我们将排序数据加载到表中时,这些是数据库计算出的相关性。
1
2
3
4
5
| tablename | attname | correlation
-----------+----------+----------------
sale_fact | id | 1
sale_fact | username | -0.00041992788
sale_fact | sold_at | 1
|
现在sold_at的相关性为1。
那么为什么数据库在相关性较低的时候使用位图扫描,而在相关性接近1的时候使用索引扫描呢?
- 当相关性为1时,数据库估计请求范围内的行很可能在连续的页面中。在这种情况下,索引扫描很可能读取很少的页面。
- 当相关性接近0时,数据库估计请求范围内的行很可能分散在整个表中。在这种情况下,使用位图扫描来映射存在行的表页是有意义的,只有这样才能获取行并应用条件。
下次将数据加载到表中时,请考虑如何查询数据,并确保以用于范围扫描的索引能够受益的方式进行排序。
CLUSTER Command
另一种按特定索引对磁盘上的表进行 “排序 “的方法是使用CLUSTER命令。
例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| db=# TRUNCATE sale_fact;
TRUNCATE TABLE
-- Insert rows without sorting
db=# INSERT INTO sale_fact (username, sold_at)
db-# SELECT
db-# md5(random()::text) AS username,
db-# '2020-01-01'::date + (interval '1 day') * round(random() * 365 * 2) AS sold_at
db-# FROM
db-# generate_series(1, 100000)
INSERT 0 100000
db=# ANALYZE sale_fact;
ANALYZE
db=# SELECT tablename, attname, correlation
db-# FROM pg_stats
db-# WHERE tablename = 'sale_fact';
tablename | attname | correlation
-----------+-----------+----------------
sale_fact | sold_at | -5.9702674e-05
sale_fact | id | 1
sale_fact | username | 0.010033822
|
我们按照随机顺序向表中加载数据,结果sold_at的相关性接近于零。
为了按sold_at对表进行 “重新排列”,我们使用CLUSTER命令,根据索引sale_fact_sold_at_ix对磁盘上的表进行排序。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| db=# CLUSTER sale_fact USING sale_fact_sold_at_ix;
CLUSTER
db=# ANALYZE sale_fact;
ANALYZE
db=# SELECT tablename, attname, correlation
db-# FROM pg_stats
db-# WHERE tablename = 'sale_fact';
tablename | attname | correlation
-----------+----------+--------------
sale_fact | sold_at | 1
sale_fact | id | -0.002239401
sale_fact | username | 0.013389298
|
表格聚类后,我们可以看到sold_at的相关性为1。
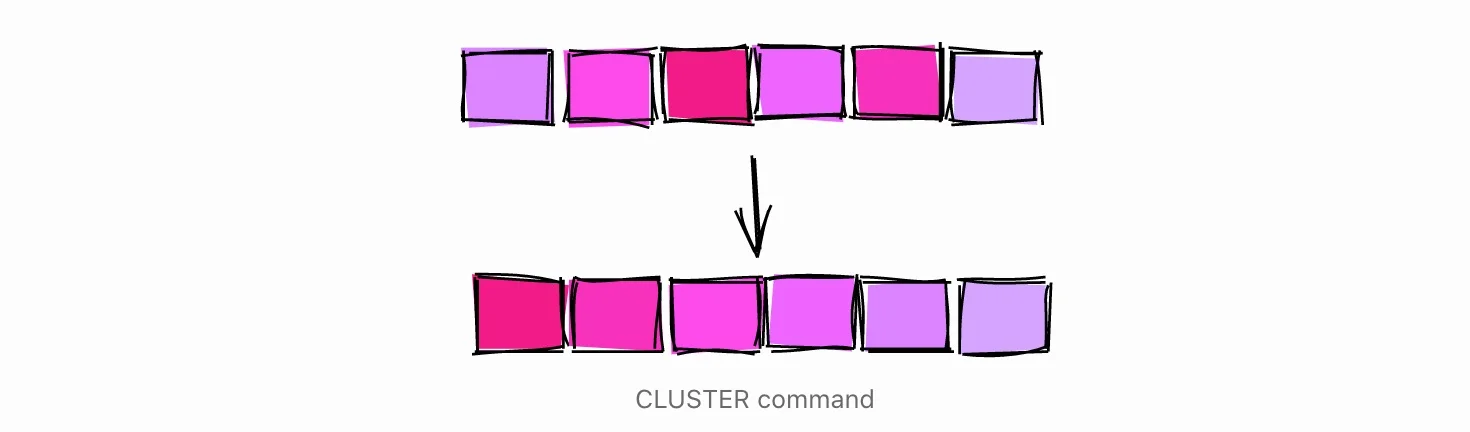
关于CLUSTER命令需要注意的一些事情。
- 通过特定列对表进行聚类可能会影响其他列的相关性。例如,请看我们将表按sold_at聚类后,列id的相关性。
- CLUSTER是一个重度、阻塞的操作,所以请确保不要在活表上执行。
基于这两个原因,最好是将数据分类插入,不要依赖CLUSTER。
使用 BRIN 索引高相关性的列
说到索引,大多数开发人员会想到B-Tree索引。但是,PostgreSQL提供了其他类型的索引,比如BRIN。
BRIN是为处理非常大的表而设计的,在这些表中,某些列与它们在表中的物理位置有一些自然的关联。
BRIN是Block Range Index的缩写。根据文档,BRIN索引对于相关性高的列效果最好。正如我们在前面的章节中已经看到的,一些字段如自动递增的ID和时间戳与表的物理结构有天然的相关性,因此它们是BRIN索引的良好候选。
在某些情况下,与类似的B-Tree索引相比,BRIN索引在大小和性能上可以提供更好的 “性价比”。
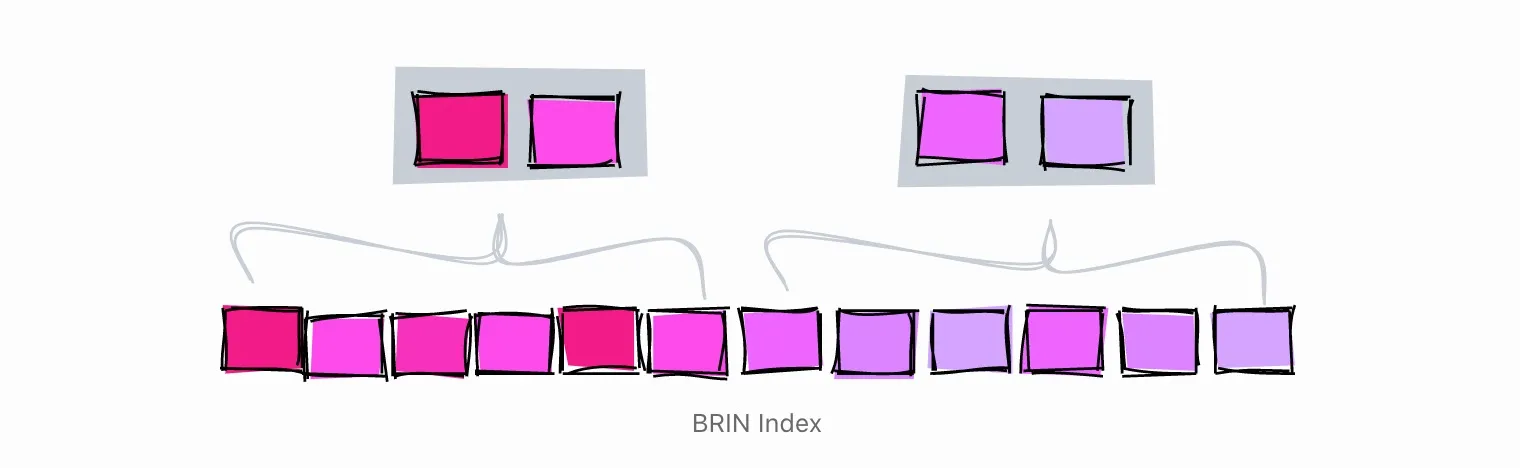
BRIN索引的工作原理是将值的范围保持在表内相邻的若干页内。假设我们在一列中有这些值,每个值都是单表页。
1, 2, 3, 4, 5, 6, 7, 8, 9
BRIN索引在表中相邻页的范围内工作。如果相邻页数设置为3,索引将把表格分为以下范围:
[1,2,3], [4,5,6], [7,8,9]
对于每个范围,BRIN指数保持最小值和最大值。
[1–3], [4–6], [7–9]
利用上面的索引,尝试搜索数值5。
- [1–3] - Definitely not here
- [4–6] - Might be here
- [7–9] - Definitely not here
利用BRIN索引,我们设法将搜索范围限制在4-6块。
让我们再举一个例子,这次列中的值会有一个接近于零的相关性,这意味着它们没有被排序。
[2,9,5], [1,4,7], [3,8,6]
将3个相邻的块进行索引,会产生以下范围。
[2–9], [1–7], [3–8]
让我们试着搜索一下数值5。
[2–9] - 可能在这
[1–7] - 可能在这
[3–8] - 可能在这
在这种情况下,索引根本没有限制搜索,因此它是没有用的。
理解 pages_per_range
相邻页面的数量由参数pages_per_range决定。每个范围的页数会影响BRIN索引的大小和精度。
大的pages_per_range会产生一个小而不准确的索引。
小的pages_per_range会产生更大更准确的索引。
默认的页面_per_range为128页。
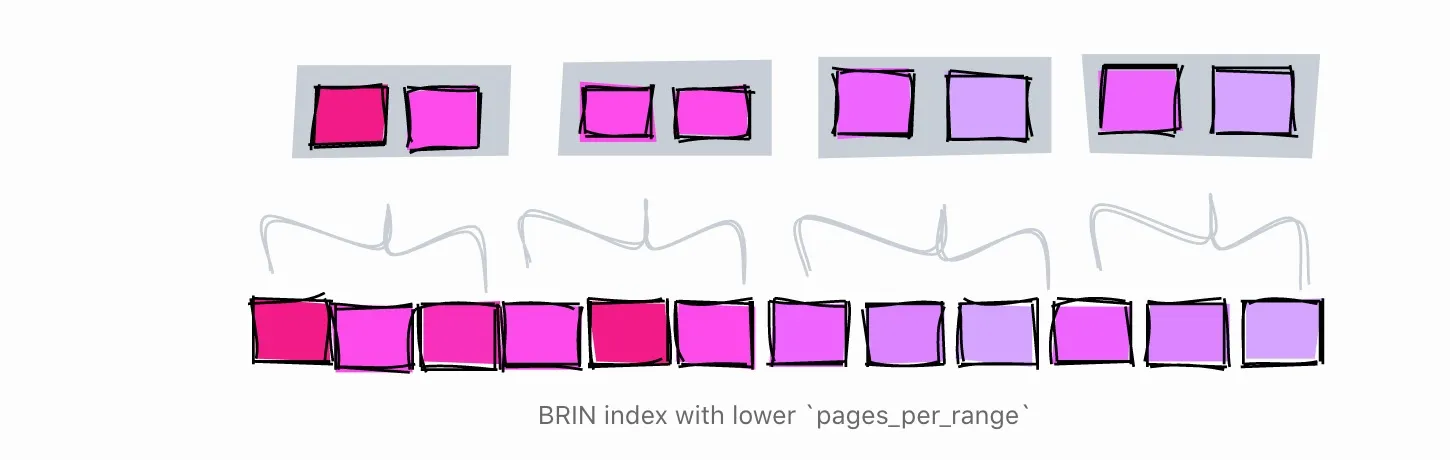
为了演示,让我们在2个相邻页面的范围上创建一个BRIN索引,并搜索值5。
- [1–2] - 肯定不在这
- [3–4] - 肯定不在这
- [5–6] - 可能在这
- [7–8] - 肯定不在这
- [9] - 肯定不在这
使用每个范围为2页的索引,我们能够将搜索限制在第5和第6块。当范围为3页时,索引将搜索范围限制在4、5和6块。
两个索引之间的另一个区别是,当范围是3页时,我们只需要保留3个范围。当范围为2时,我们必须保留5个范围,所以索引更大。
创建 BRIN 索引
使用之前的sales_fact,让我们在sold_at列上创建一个BRIN索引。
1
2
3
| db=# CREATE INDEX sale_fact_sold_at_bix ON sale_fact
db-# USING BRIN(sold_at) WITH (pages_per_range = 128);
CREATE INDEX
|
这就创建了一个BRIN索引,默认的页面_per_range = 128。
让我们尝试查询销售日期的范围。
1
2
3
4
5
6
7
8
9
10
11
12
13
| db=# EXPLAIN (ANALYZE)
db-# SELECT *
db-# FROM sale_fact
db-# WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
--------------------------------------------------------------------------------------------
Bitmap Heap Scan on sale_fact (cost=13.11..1135.61 rows=4319 width=41)
Recheck Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Rows Removed by Index Recheck: 23130
Heap Blocks: lossy=256
-> Bitmap Index Scan on sale_fact_sold_at_bix (cost=0.00..12.03 rows=12500 width=0)
Index Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Execution Time: 8.877 ms
|
数据库使用我们的BRIN索引得到了一系列的销售日期,但这不是有趣的部分……。
优化 pages_per_range
根据执行计划,数据库从使用索引找到的页面中删除了23130条记录。这可能表明我们为索引设置的范围对于这个特定的查询来说太大。让我们尝试创建一个每个范围内页数较少的索引。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| db=# CREATE INDEX sale_fact_sold_at_bix64 ON sale_fact
db-# USING BRIN(sold_at) WITH (pages_per_range = 64);
CREATE INDEX
db=# EXPLAIN (ANALYZE)
db- SELECT *
db- FROM sale_fact
db- WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
---------------------------------------------------------------------------------------------
Bitmap Heap Scan on sale_fact (cost=13.10..1048.10 rows=4319 width=41)
Recheck Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Rows Removed by Index Recheck: 9434
Heap Blocks: lossy=128
-> Bitmap Index Scan on sale_fact_sold_at_bix64 (cost=0.00..12.02 rows=6667 width=0)
Index Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Execution Time: 5.491 ms
|
在每个范围为64页的情况下,数据库从使用索引找到的页面中删除的记录较少,只删除了9,434条,而当范围为128页时,删除了23,130条。这意味着数据库需要做更少的IO,查询速度也稍快,约5.5ms,而不是约8.9ms。
用不同的pages_per_range值测试索引,产生了以下结果。
1
2
3
4
5
6
| PAGES_PER_RANGE ROWS_REMOVED_BY_INDEX_RECHECK
128 23,130
64 9,434
8 874
4 446
2 446
|
我们可以看到,当我们减少pages_per_range时,索引更加准确,并且从使用索引找到的页面中删除的行数更少。
注意,我们针对一个非常特殊的查询进行了优化。这对于演示目的来说是可以的,但在实际生活中,最好使用满足大多数查询需求的值。
评估指数大小
BRIN索引的另一大卖点是其大小。在前面的章节中,我们在sold_at字段上创建了一个B-Tree索引。该索引的大小是2224kB。page_per_range=128的BRIN索引的大小只有48kb。这比B-Tree索引小了46倍。
1
2
3
4
| Schema | Name | Type | Owner | Table | Size
--------+-----------------------+-------+-------+-----------+-------
public | sale_fact_sold_at_bix | index | haki | sale_fact | 48 kB
public | sale_fact_sold_at_ix | index | haki | sale_fact | 2224 kB
|
BRIN索引的大小也会受到pages_per_range的影响。例如,page_per_range=2的BRIN索引重56kb,仅比48kb稍大。
让索引 “不可见”
PostgreSQL有一个很好的功能,叫做事务性DDL。在使用Oracle多年后,我已经习惯了诸如CREATE、DROP和ALTER等结束事务的DDL命令。然而,在PostgreSQL中,你可以在事务中执行DDL命令,而且只有当事务提交时,更改才会生效。
正如我最近发现的那样,使用事务性DDL,你可以使索引不可见! 当你想看看一个执行计划在没有一些索引的情况下是什么样子的时候,这就很方便了。
例如,在上一节的sale_fact表中,我们在sold_at上创建了一个索引。获取7月份销售额的执行计划是这样的。
1
2
3
4
5
6
7
8
| db=# EXPLAIN
db-# SELECT *
db-# FROM sale_fact
db-# WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
--------------------------------------------------------------------------------------------
Index Scan using sale_fact_sold_at_ix on sale_fact (cost=0.42..182.80 rows=4319 width=41)
Index Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))P
|
为了看看如果索引sale_fact_sold_at_ix不存在,执行计划会是什么,我们可以在一个事务里面放弃索引,然后立即回滚。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| db=# BEGIN;
BEGIN
db=# DROP INDEX sale_fact_sold_at_ix;
DROP INDEX
db=# EXPLAIN
db-# SELECT *
db-# FROM sale_fact
db-# WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
---------------------------------------------------------------------------------
Seq Scan on sale_fact (cost=0.00..2435.00 rows=4319 width=41)
Filter: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
db=# ROLLBACK;
ROLLBACK
|
我们首先使用BEGIN开始一个事务。然后我们放弃索引并生成一个执行计划。注意,现在执行计划使用了全表扫描,就像索引不存在一样。此时事务仍在进行中,所以还没有丢弃索引。为了在不丢弃索引的情况下完成事务,我们使用ROLLBACK命令回滚事务。
现在,确保索引仍然存在。
1
2
3
4
5
| db=# \di+ sale_fact_sold_at_ix
List of relations
Schema | Name | Type | Owner | Table | Size
--------+----------------------+-------+-------+-----------+---------
public | sale_fact_sold_at_ix | index | haki | sale_fact | 2224 kB
|
其他不支持事务性DDL的数据库提供了其他方法来实现同样的目标。例如,Oracle让你将一个索引标记为不可见,这将导致优化器忽略它。
注意:在事务内部丢弃索引会在事务处于活动状态时锁定表的并发选择、插入、更新和删除。请在测试环境中谨慎使用,并避免在生产数据库中使用。
不要在圆周时间安排长期运行的流程
众所周知,当一只股票的价格达到一个漂亮的整数,如10元、100元、1000元时,就会发生奇怪的事情,这是投资者都知道的事实。正如下面的文章所解释的。
[… …]资产的价格可能会有一个困难的时间 超过一个整数,如50元或100元/股。大多数没有经验的交易者倾向于在价格处于整数时买入或卖出资产,因为他们更有可能觉得一只股票在这种水平上的价值相当高。
开发商在这个意义上与投资者并没有什么不同。当他们需要安排一个长期运行的过程时,他们通常会把时间安排在一个整点。
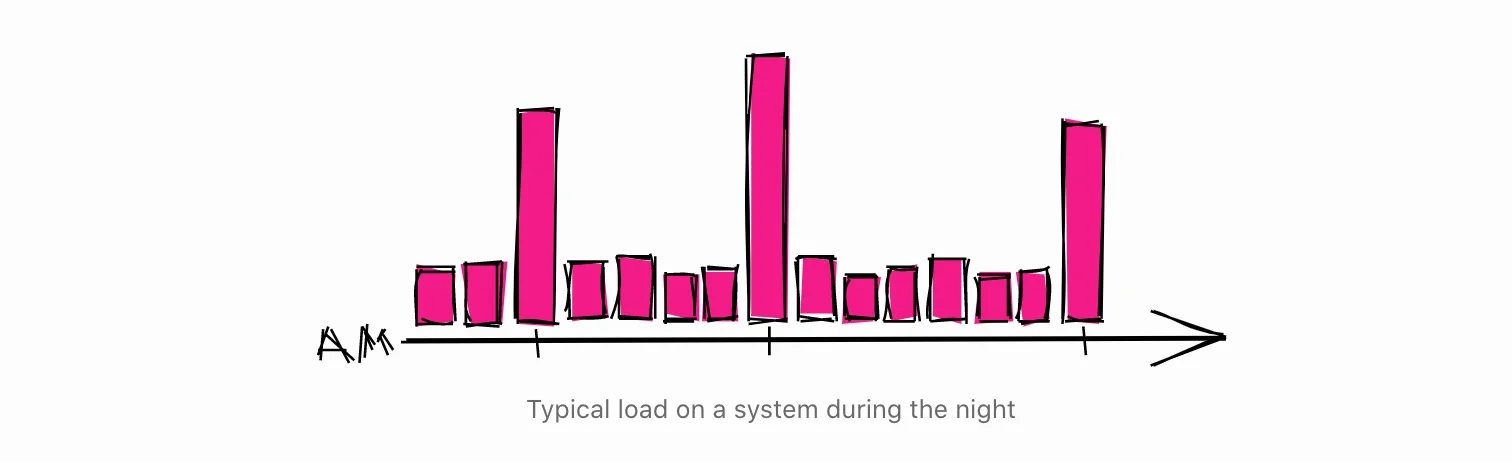
这种在圆周时间安排任务的倾向,会在这些时间内造成一些异常的负载。所以,如果你需要安排一些长期运行的进程,如果你在其他时间安排,你有更好的机会找到一个系统在休息。
另一个好主意是给任务的日程安排应用一个随机的延迟,这样它就不会每次都在同一时间运行。这样,即使另一个任务安排在同一时间运行,也不会有大问题。如果你使用systemd定时器单元来安排任务,你可以使用RandomizedDelaySec选项来实现。
结束语
本文涵盖了我自己经验中的一些琐碎和非琐碎的技巧。其中有些技巧很容易实现,有些则需要更深入地了解数据库的工作原理。数据库是大多数现代系统的支柱,所以花一些时间来了解它们的工作原理对任何开发人员来说都是一项很好的投资!