简介
Elastic Workplace Search 提供了一个统一的搜索体验,从而便于任何人在任何时间找到所需的文档信息。为企业搭建了一个横跨所有工作内容、所有团队和真相的统一搜索参考平台。
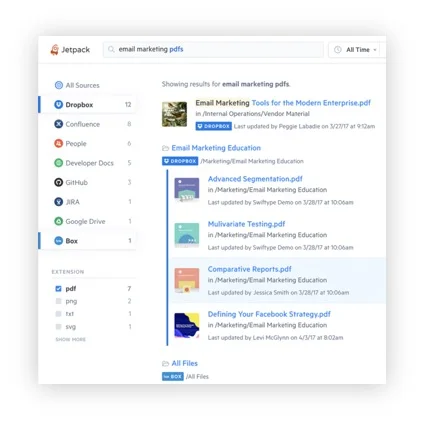
这个搜索平台能够对接各种数据源,并且实现文档内容级别的索引,目前所支持的数据源包括:OneDrive、SharePoint、ServiceNow、Box、Dropbox、Github、Github Enterprise、Google Drive、JIRA、Confluence、Salesforce、Zendesk 等。
它具有以下特点:
- 配置部署简单,缩短了系统上线和等待时间。不像是传统的消耗数个月甚至一年都无法完成的搜索项目,这个解决方案可以让企业在几天或几周内就能投入使用。
- 个性化定制的搜索体验。通过 Elasticsearch 所提供的搜索能力,管理员可以控制企业、团队级别的数据源,个体用户可以控制自己的私有数据源,所有级别上都可以调整相关度权重,从而提高搜索结果的准确性和实用性
- 提供各种自然语言的和关键字的搜索。系统提供了强大的语言分析和关键字检测能力,用户可以使用任意关键字和搜索开关轻松的搜索到所需的信息。
- 具备丰富的开箱即用功能:无须开发即可实现用户管理、数据源管理、基于用户和组的数据源可见性设置、数据源对不同用户和组的权重等功能。
系统安装配置
本文的假设,文中所使用的安装包和需要部署的配置文件都在 /vagrant 这个目录下面。下面的所有命令中都假设从这个目录里选用和复制。配置文件见代码库:https://github.com/martinliu/elastic-labs
本文所使用的安装测试环境是:
- CentOS Server 8
- JDK 11
- Elasticsearch 7.6.1
- Kibana 7.6.1
- Elastic Workplace Search 7.6.1
下面使用 vagrant up 一键式拉起基础测试环境的说明,请参考之前的文章。本测试所使用的基础 ES 安装脚本如下。
| |
这段脚本配合 vagrant 的 provision 功能使用,它本来就是一段 shell 脚本,可以可以独立执行,它的输出结果如下。
使用 vagrant up 命令拉起了测试虚拟机之后,在屏幕的输出信息中复制出 elastic 用户的密码。
| |
本示例使用了 elasticsearc-native 的用户认证模式。 为了方便起见,安装了 Kibana 7.6.1 ,过程此处忽略;在 Kibana 的用户管理中创建如下用户:
- sales1 、 sales2
- dev1 、 dev2
示例如下图所示。
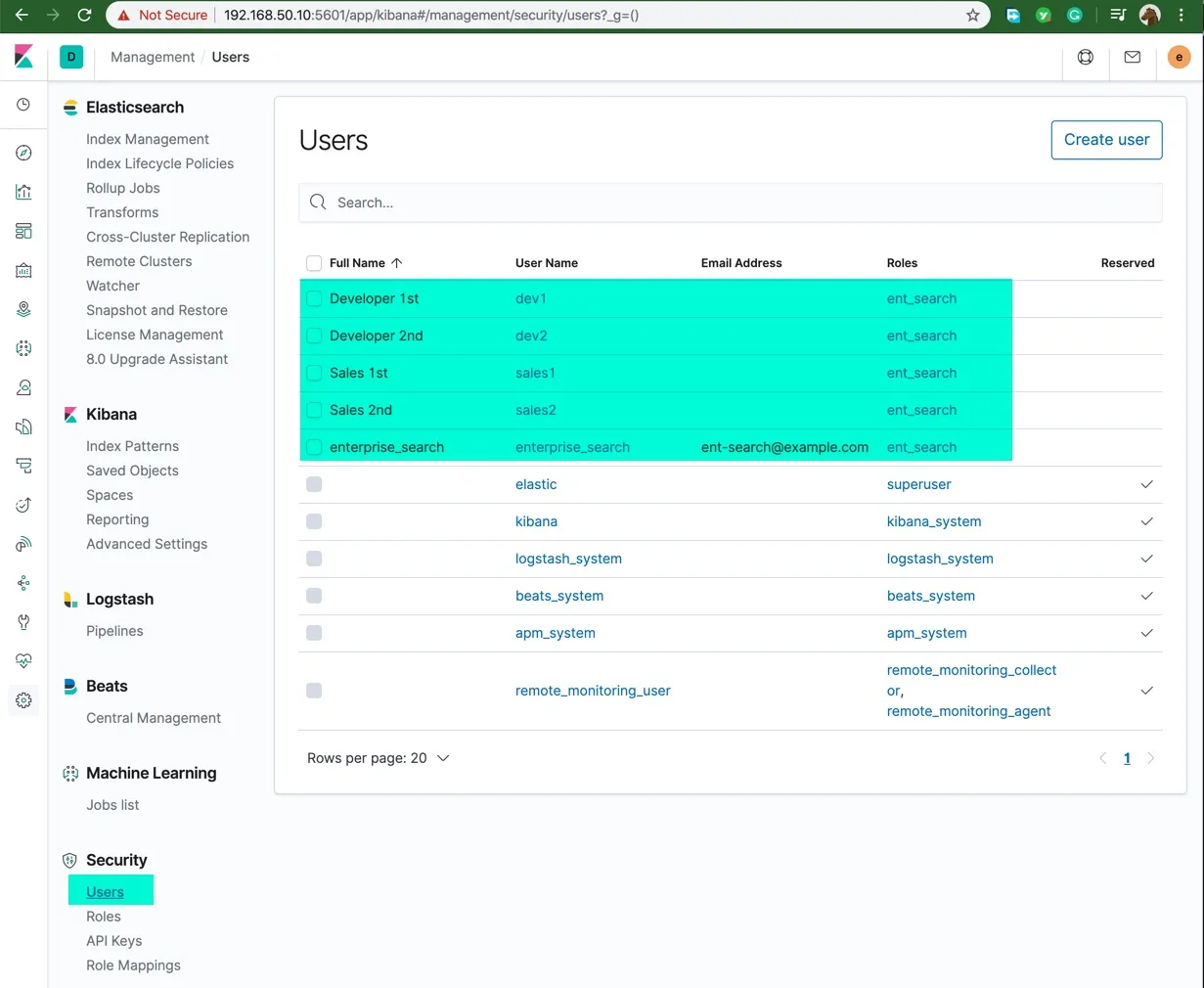
这些是测试用户,用于 Elastic Workplace Search 的测试中。
安装 Elastic Enterprise Search
Elastic Enterprise Search 需要 JDK 8 或者 JDK 11, 本实例安装了 Oracle JDK 11。
sudo rpm -ivh /vagrant/rpm/jdk-11.0.6_linux-x64_bin.rpm
复制 Enterprise Search 的安装包到 /opt 目录下,解压缩这个安装包。
| |
在 Enterprise Search 的配置文件中加入 elastic 用户的密码等配置信息。并且将配置文件部署到测试服务器中。本实例的配置文件 enterprise-search.yml 内容如下。
| |
将以上目标配置文件复制到 Elastic Workplace Search 的配置文件目录中,覆盖默认配置文件。
| |
启动 Enterprise Search 服务器,并且设置默认的管理员密码。
| |
在启动的过程中,关注一下的屏幕输出信息,则表示一切正常。
| |
等待服务器启动正常后,参考相关文档。完成 Github、Jira 和 Confluence 等数据源的配置。
配置数据源
见介绍文档 https://www.elastic.co/guide/en/workplace-search/current/workplace-search-content-sources.html
- Confluence Cloud
- Confluence Server
- Dropbox
- GitHub
- Google Drive
- Jira Cloud
- Jira Server
- OneDrive
- Salesforce
- ServiceNow
- SharePoint Online
- Zendesk
除了默认支持以上数据源外,还可以使用 Custom API 实现自己的数据源接入。数据源的类型分:
- 组织级:可以分配给个人和用户组
- 私有级:用户个体接入某个数据源,而仅供自己使用
GitHub 数据源对接
首先你需要属于 GitHub 的一个组织,或者多个组织,然后在某个组织,或者几个组织做为一个数据源,对接到 Elastic Workplace Search 中。具体的配置步骤如下.
在 GitHub 中找到需要搜索的组织,每个 repo 的 issue 和 pr 都是全文搜索的目标。
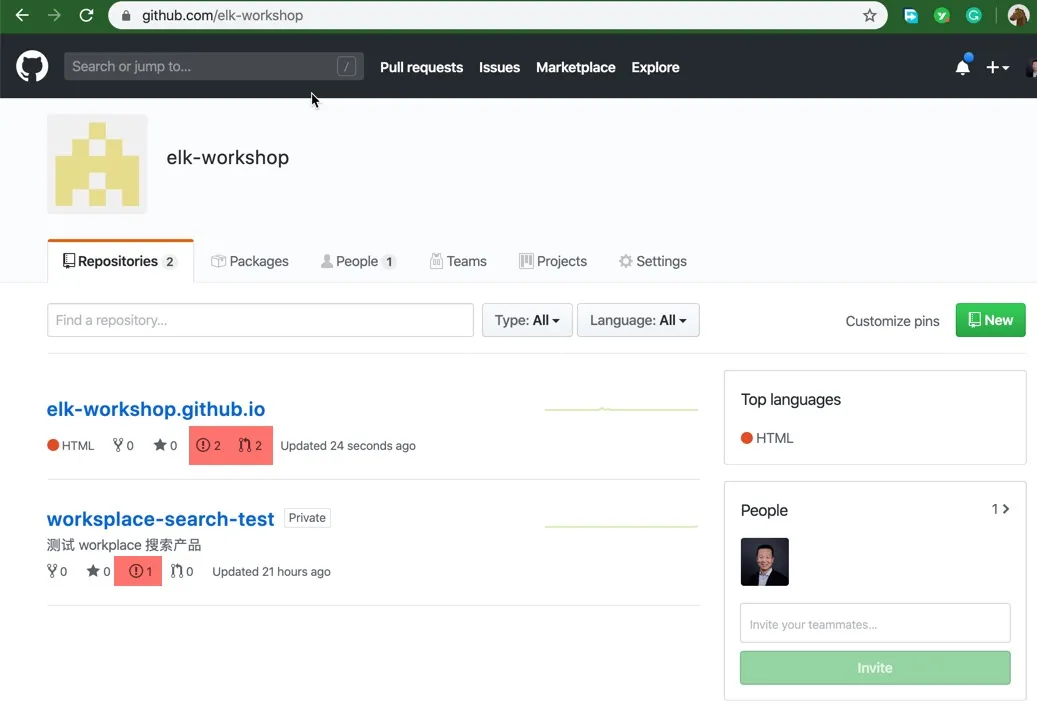
在 GitHub 的账户中创建一个 OAuth App,图中 1、2、3、4 信息点需要和你的测试环境匹配。复制出 client ID 和 Client Secret 备用。
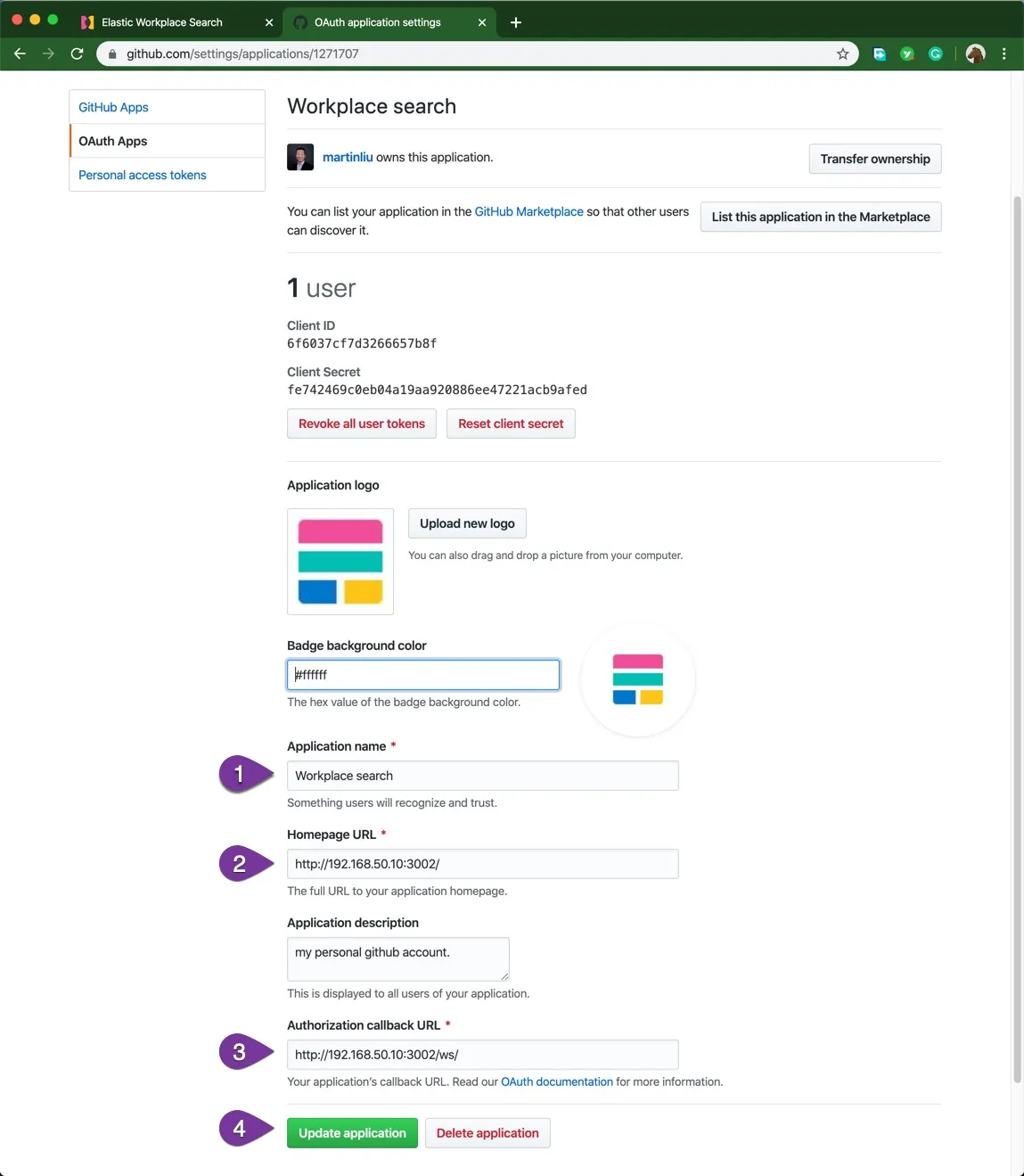
在 Elastic Workplace Search 的数据源配置页面创建 GitHub 数据源。填入上一步的两个 ID。
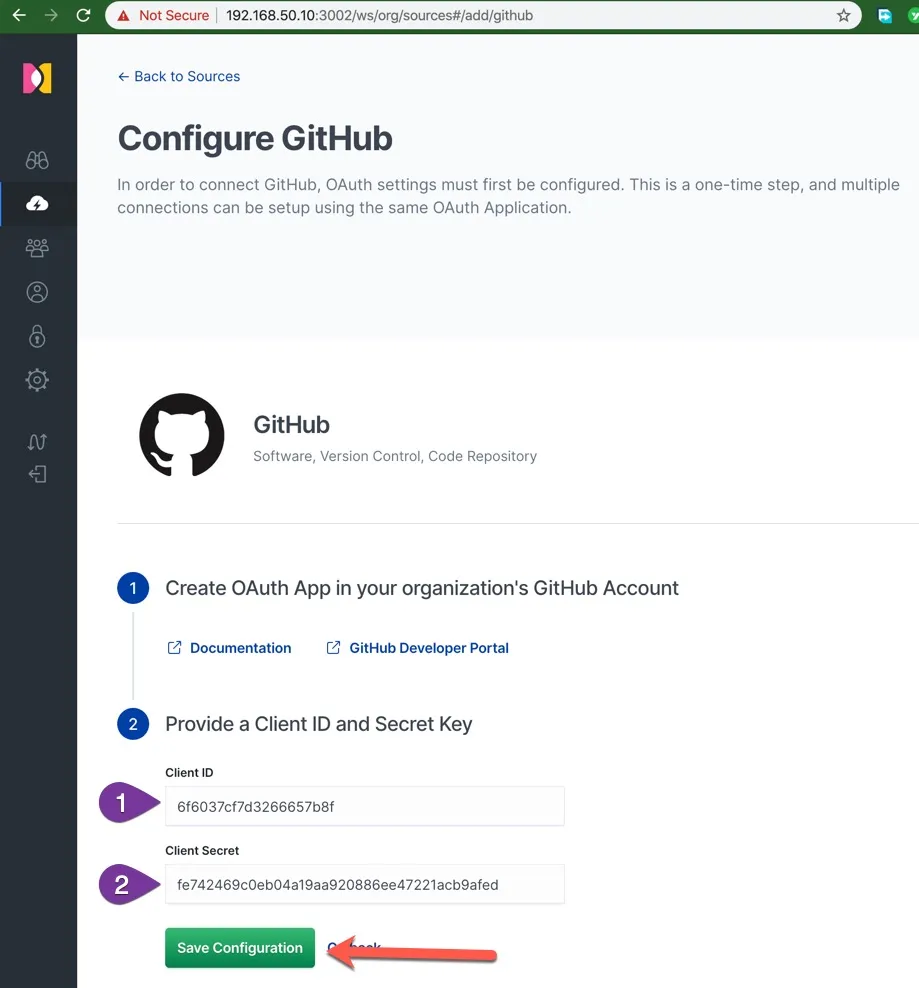
保存以上配置后,在这一步点击 Connect GitHub。
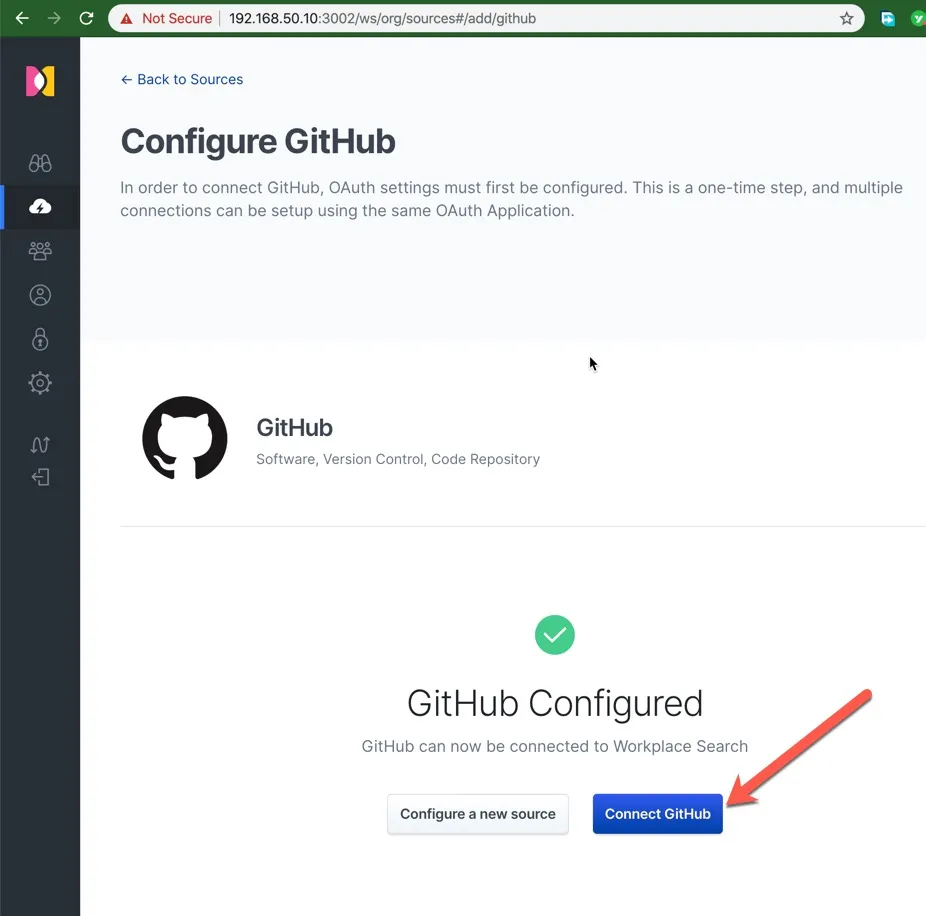
在这一步选择需要搜索的组织,勾选后,点击完成连接配置。
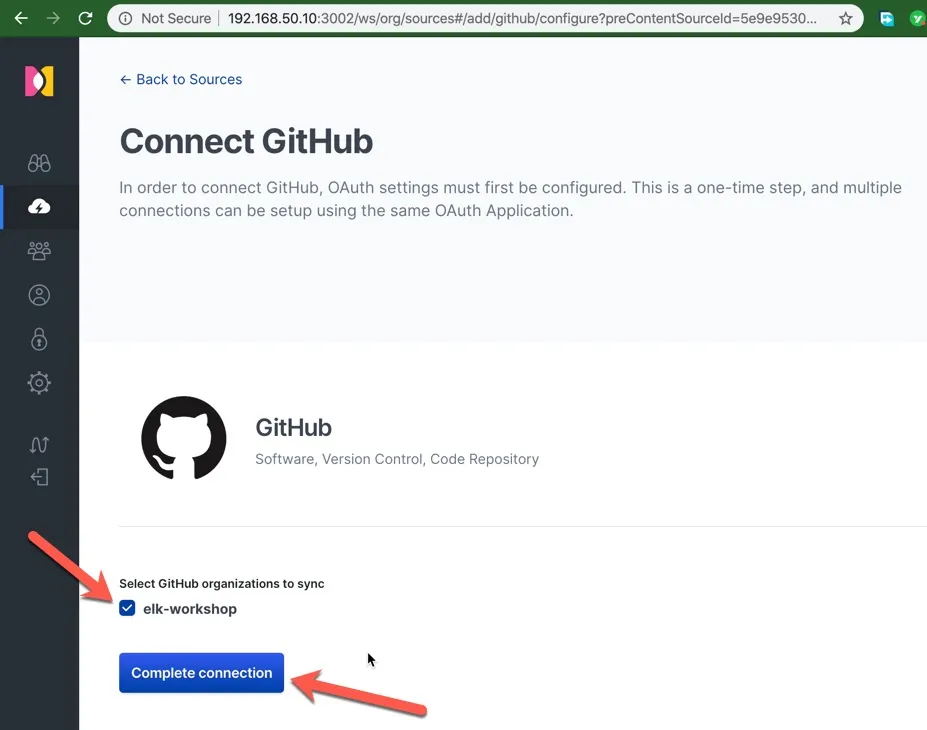
正常连接成功后,就可以看到这个组织里所有 repo 中的 issue 和 pr 了。
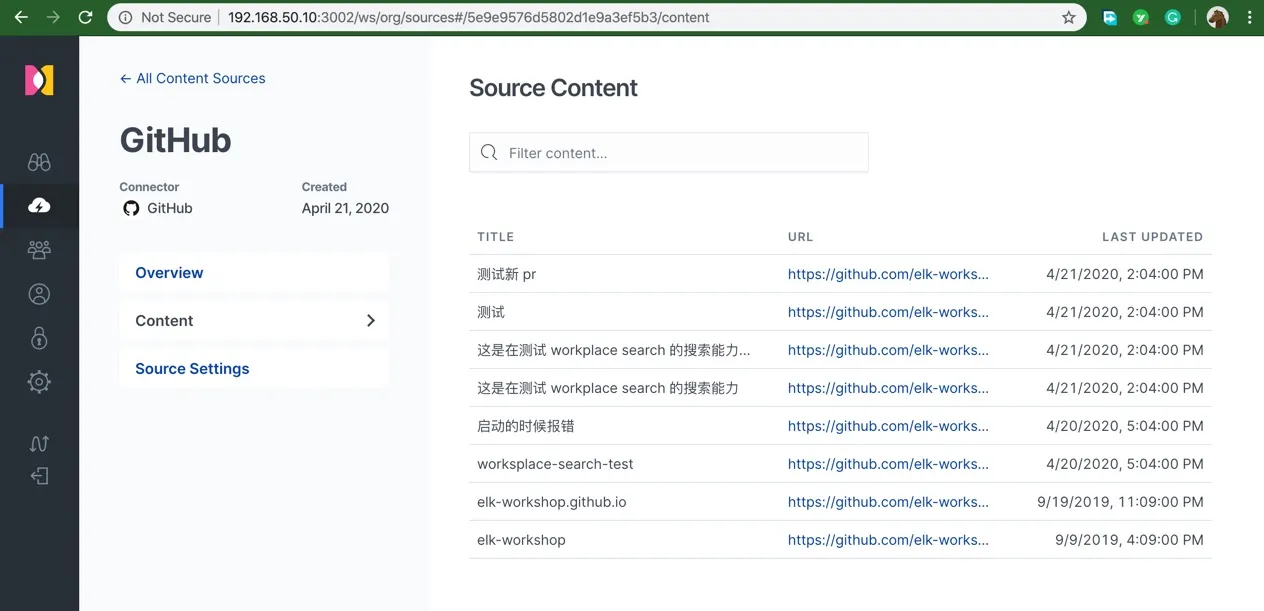
Atlassion 数据源对接
支持对 Confluence 和 Jira 两款产品的云服务和本地部署的搜索。配置的过程非常简单, 如果你有多套独立的 Confluence 和 Jira 环境,那么就可以给每个需要搜索的环境配置一个数据源,并且按照需要将对它们的统一搜索配置到一个统一的搜索平台之内。
配置文档见: https://www.elastic.co/guide/en/workplace-search/current/workplace-search-confluence-cloud-connector.html 和其它。下面是一个配置成功的 Jira 云服务的结果。
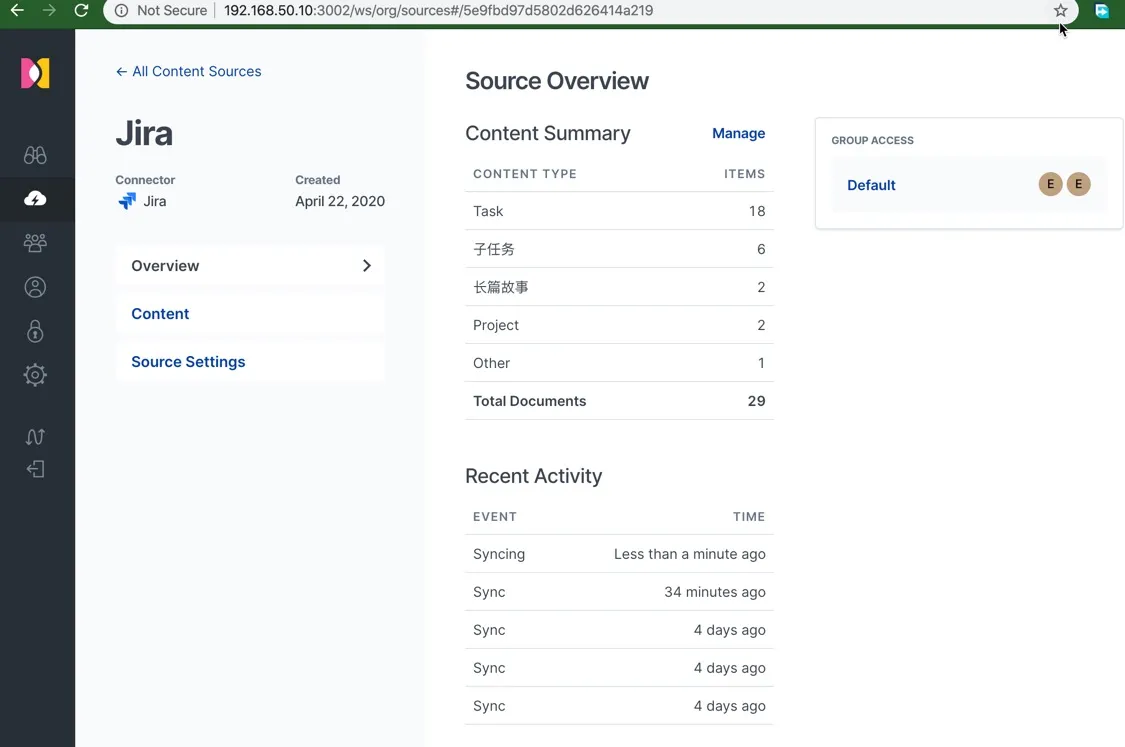
如果所示,每套 Atlassion 环境的产品都可以仅仅通过配置接入这个搜索平台。Jira 中索引的内容类型如下:
- Task
- 子任务
- 长篇故事
- Project
- Other
配置完成以后,默认的同步周期是 2 小时做一次增量索引。下图是用户对 Jira 和 Confluence 的两个本地部署服务器联合统一搜索的效果。管理员可设置任何一个人和用户组能搜索那些数据源,每个数据源在搜索结果中的权重排位。从而实现对任何一个用户组定制化搜索结果的作用。
用户配置示例
本文的目标是给两个用户组的人分配不同的数据源权重,从而得到各异的搜索结果排名。下面是一些建议的思路和配置过程。
这里把仅有的两个数据源设置成了组织级别的可搜索,也就是他可以进入任何一个合法用户的搜索清单中。加入是特定团队所使用的数据源,在这里需要关闭搜索开关。
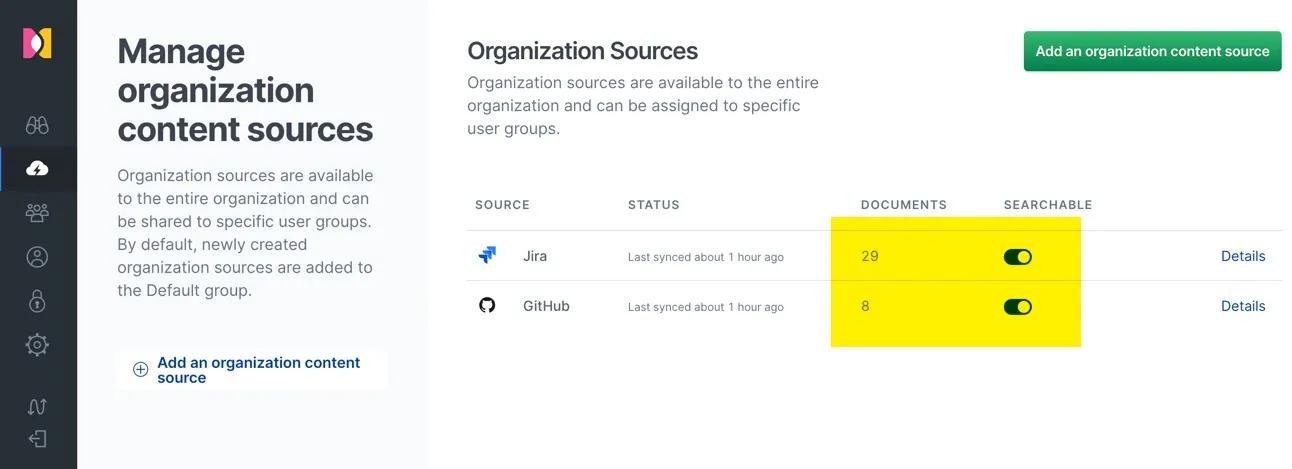
本文使用的 Elasticsearc 原生用户的认证,示例中将用户名为 sales* 开头的的用户名分配到 Elastic Workplace Search 的 “销售&市场” 组中。
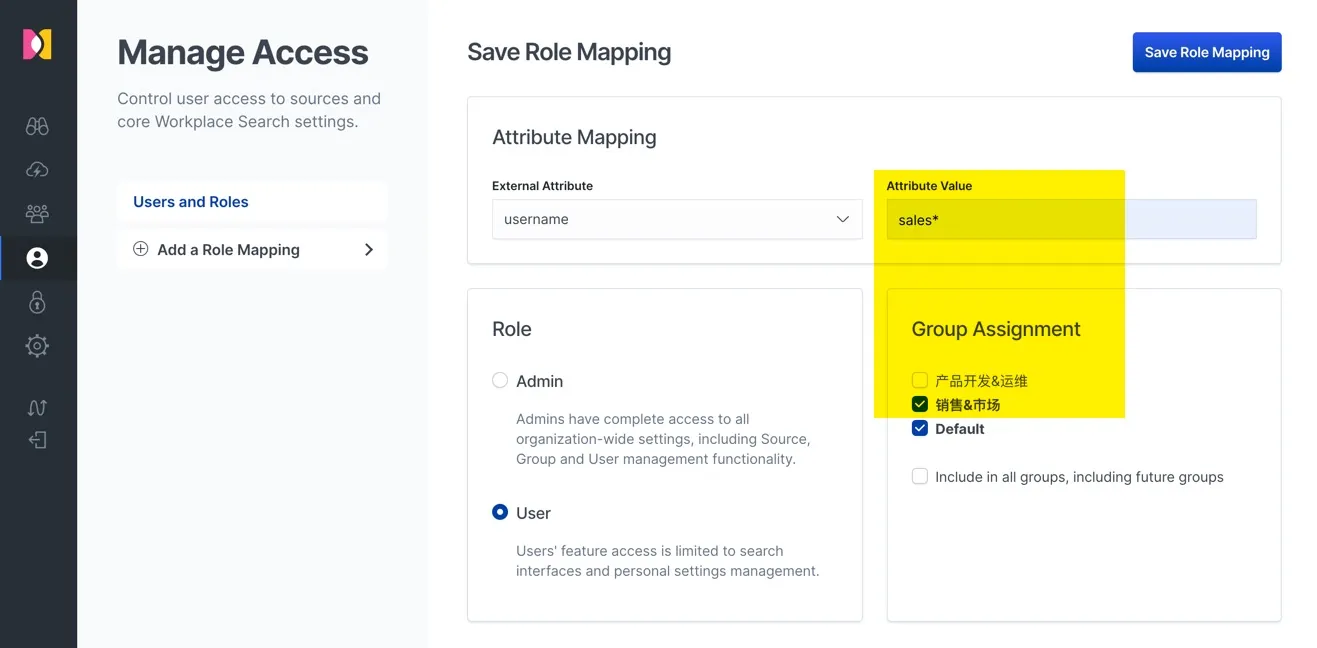
示例中将用户名为 dev* 开头的的用户名分配到 Elastic Workplace Search 的 “产品开发和运维” 组中。这里只是示例,你可以用任何已知用户与搜索用户组的对应,从而满足你的使用场景。
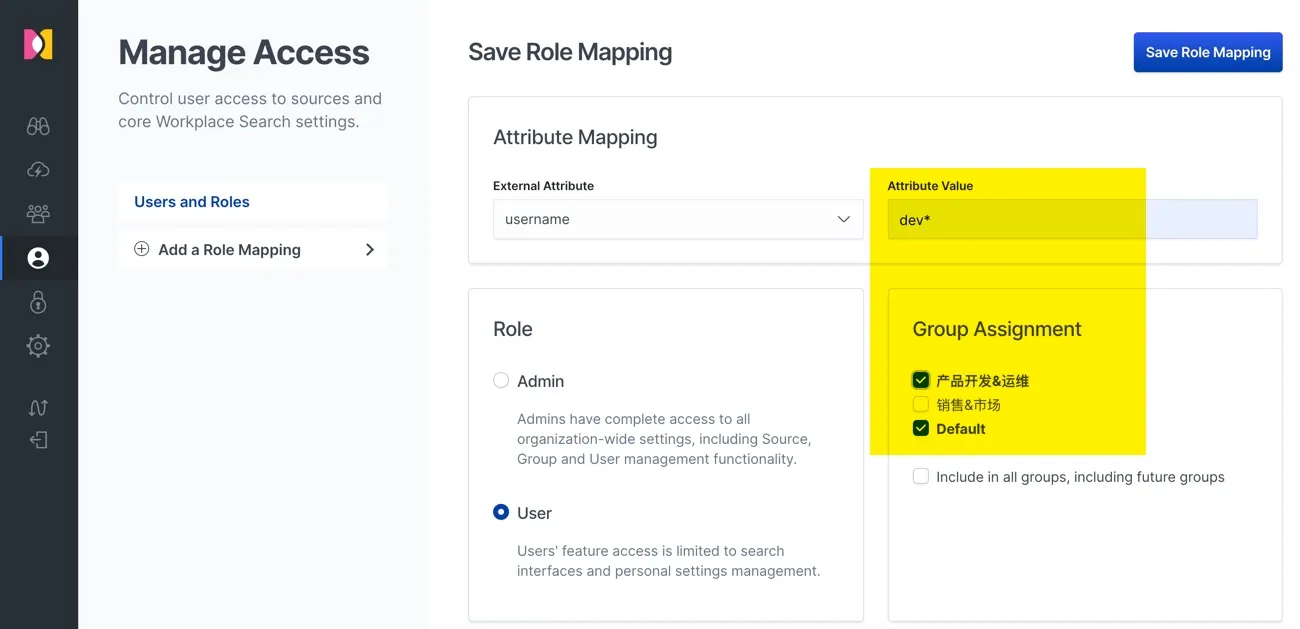
在组织级别的组属性设置中,先设置默认用户的数据源权重,这里使用默认的 1,也就是不区分两个数据源的权重,使用相同权重。
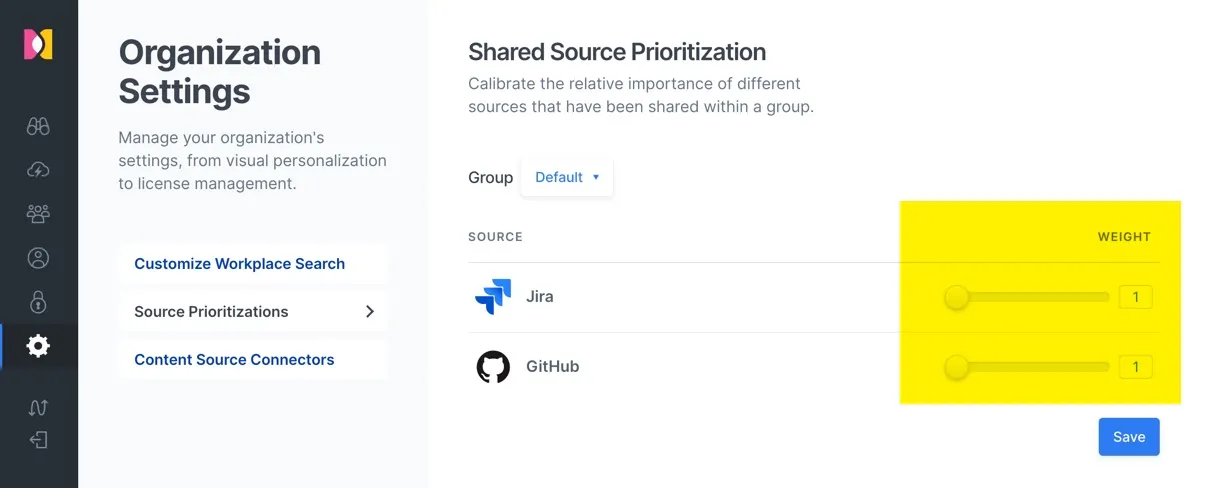
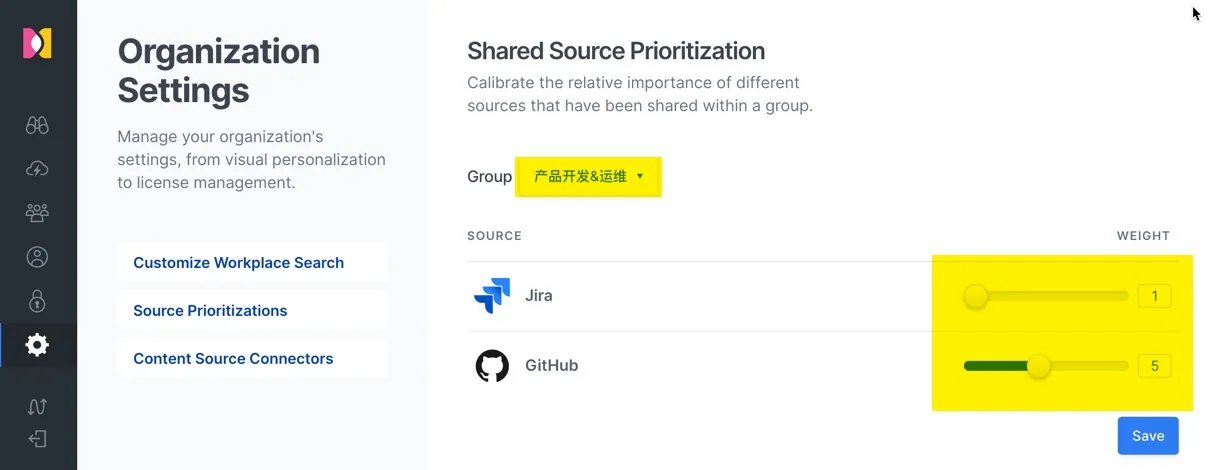
下面是对 “销售&市场” 组的数据源权重设置,这里假设这个组的人员可能更会搜索 Jira 中的关于项目开发、问题解决进展这类的信息,不会太关注工程师实际解决的代码相关的问题。因此将 Jira 中的权重从 1 增加到 5 ,从而在相同关键字中,提升 Jira 中搜索结果的整体排名。
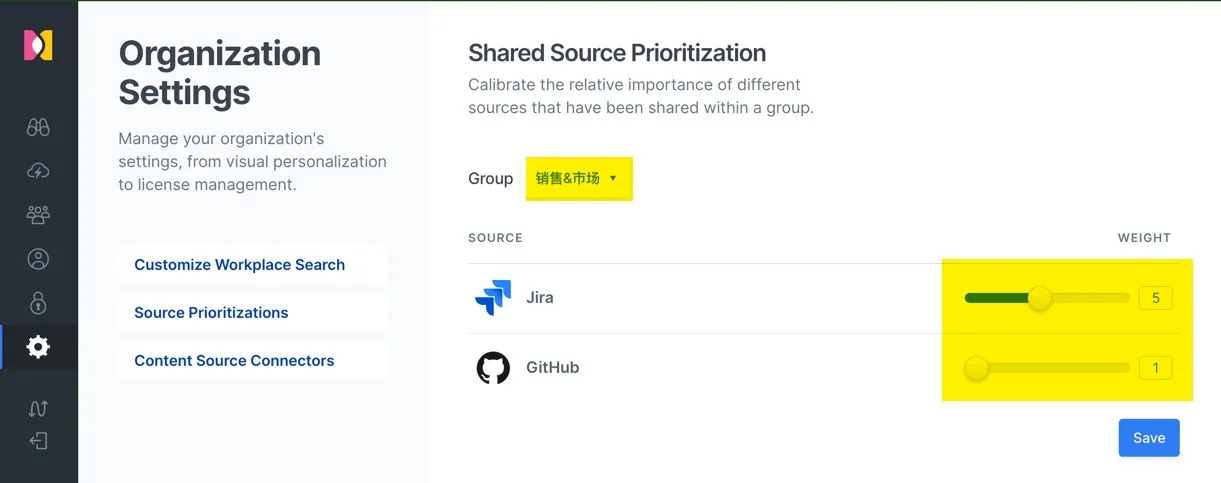
同理为 “产品开发&运维” 团队设置 GitHub 的高权重。
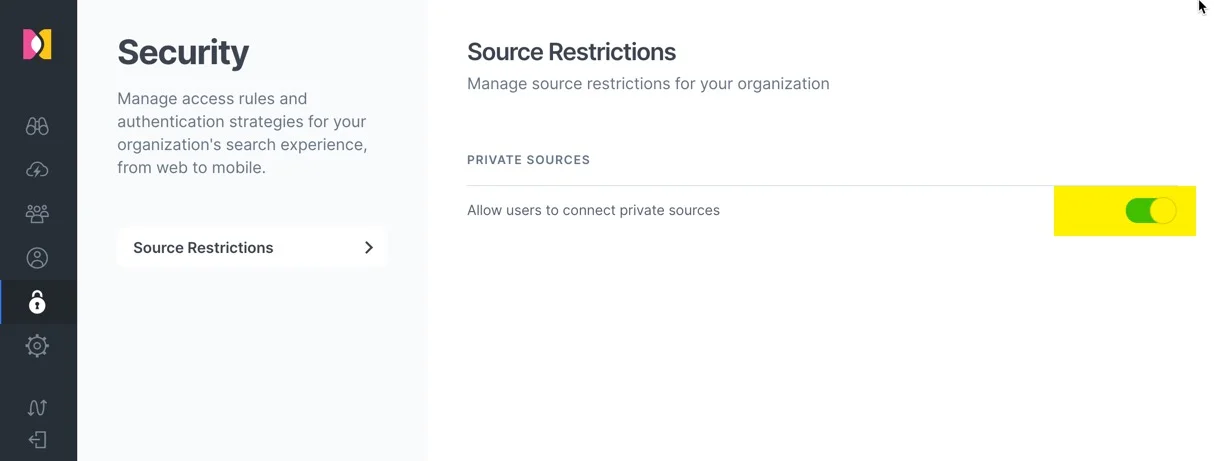
最后在这个安全的选项设置中,开启了搜索用户可以自主添加数据源的情况,也就是说这部分是个性化的数据源,可能是自己所使用的网盘,或者个人的 GitHub 组织等等,都可以!用户可以将对自己有帮助的,需要搜索的数据源都自助式的添加上,从而提高自己的工作效率。
搜索效果确认
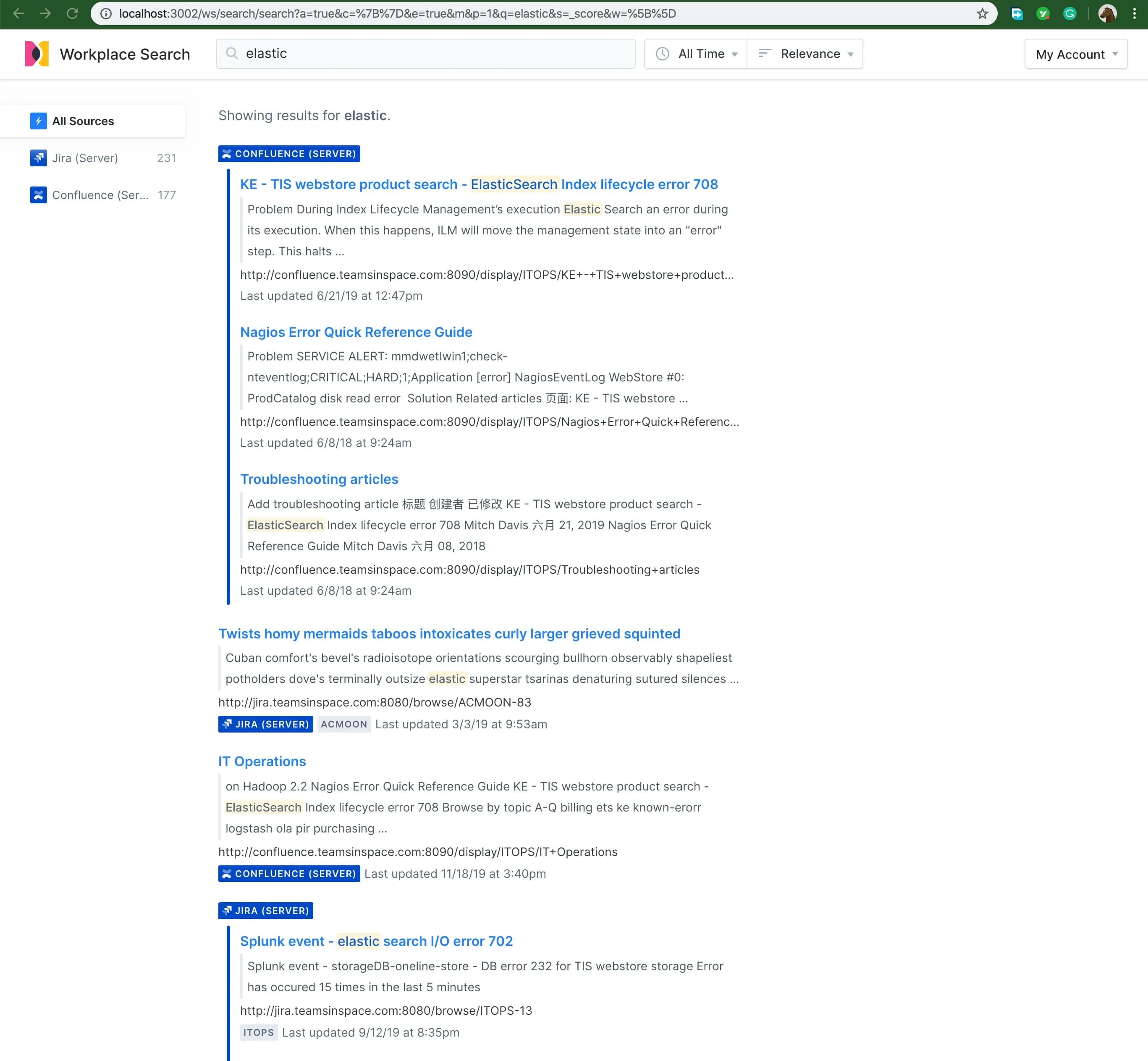
下面是用户 sales1 搜索 ealsticsearch 关键字的结果示意图。
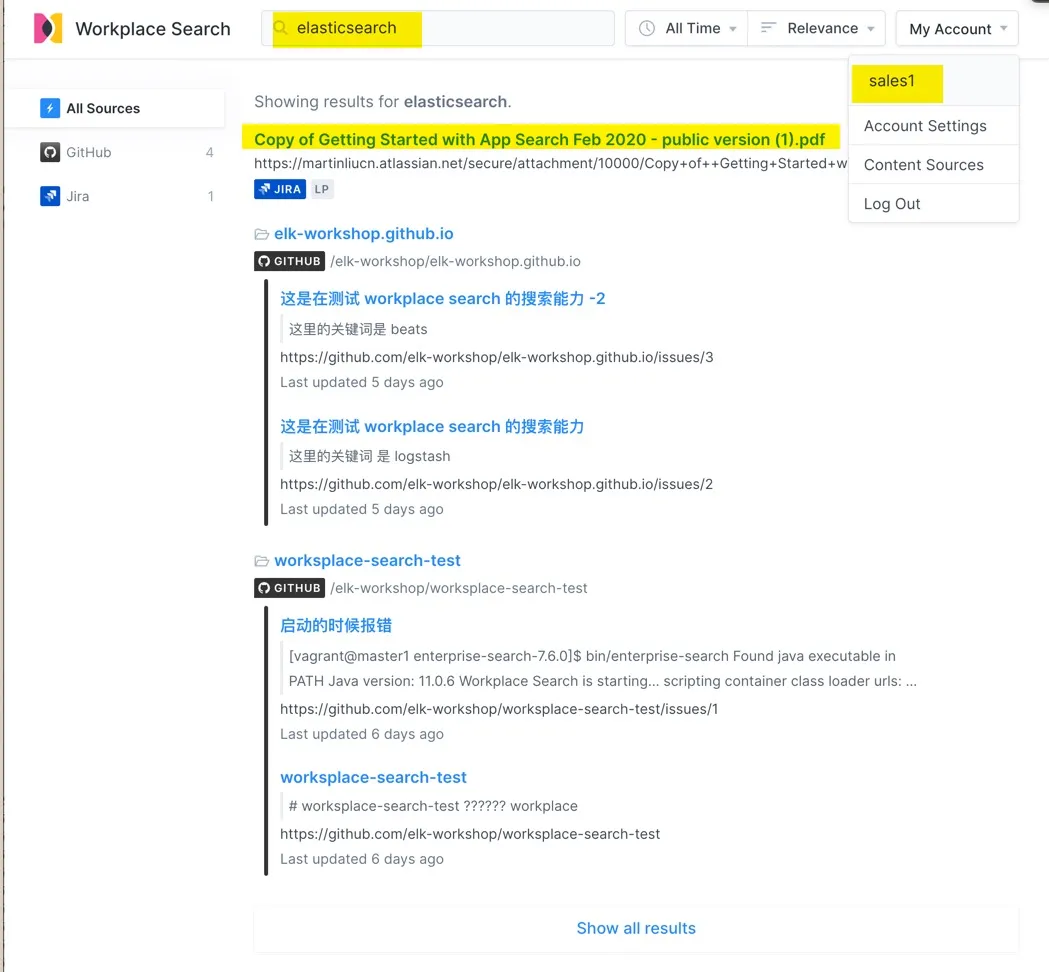
在上图中,搜索用户可以点击右侧的数据源图标,点选其中的一个数据源作为搜索范围,可以点击 All Time 时间设置条件,筛选出目标时段的文档等。还可以在搜索框中使用类似 ppt 等文件类型搜索条件。 搜索结果是故意设置的,这是 Jira 中的一个 pdf 附件,pdf 的原文也可以搜索,而且对于 销售&市场 用户组来说, Jira 的权重大于 GitHub 很多,因此即使 Github 中有四个匹配的结果,也就将其排了在了最下面。
下图是 dev1 用户(属于产品开发&运维组)的登录后界面。这里显示了建议的搜索快捷短语 pull requests form last week ,页面上的搜索结果是按照数据源中最更新的文档靠前的规则排列的。
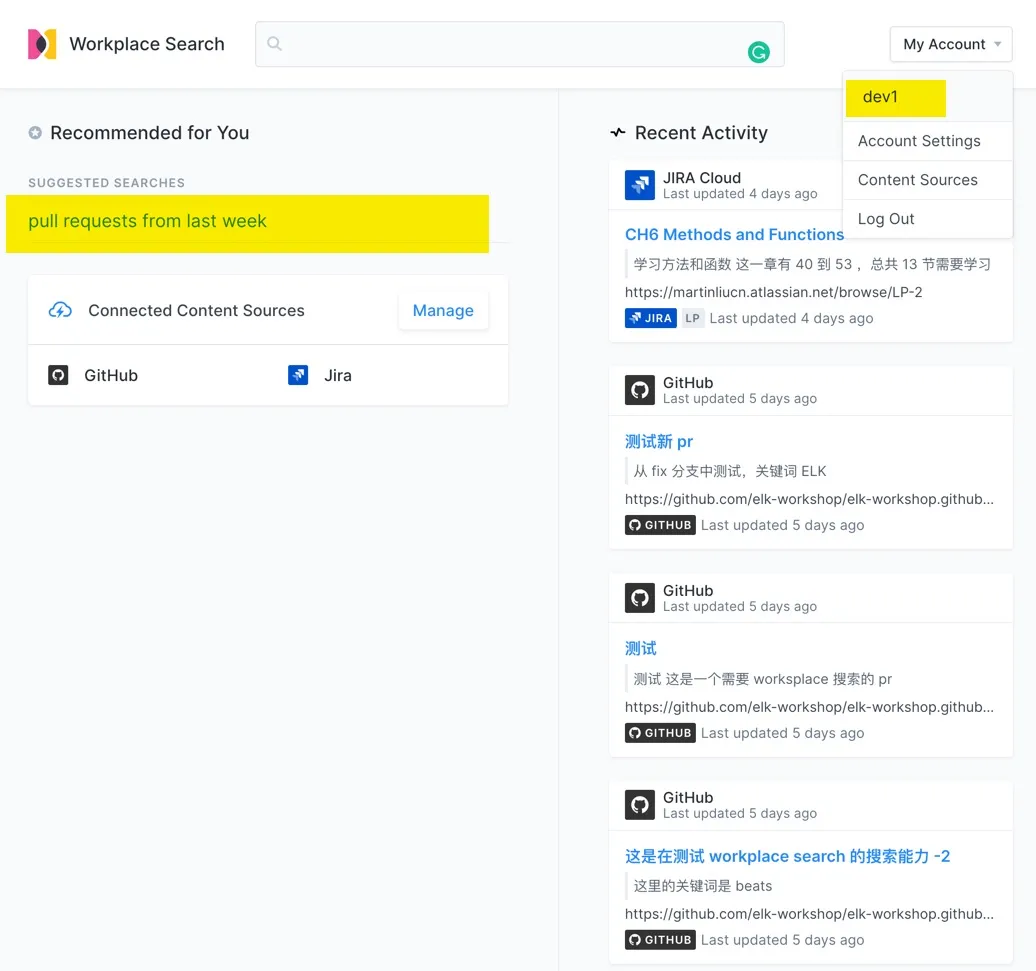
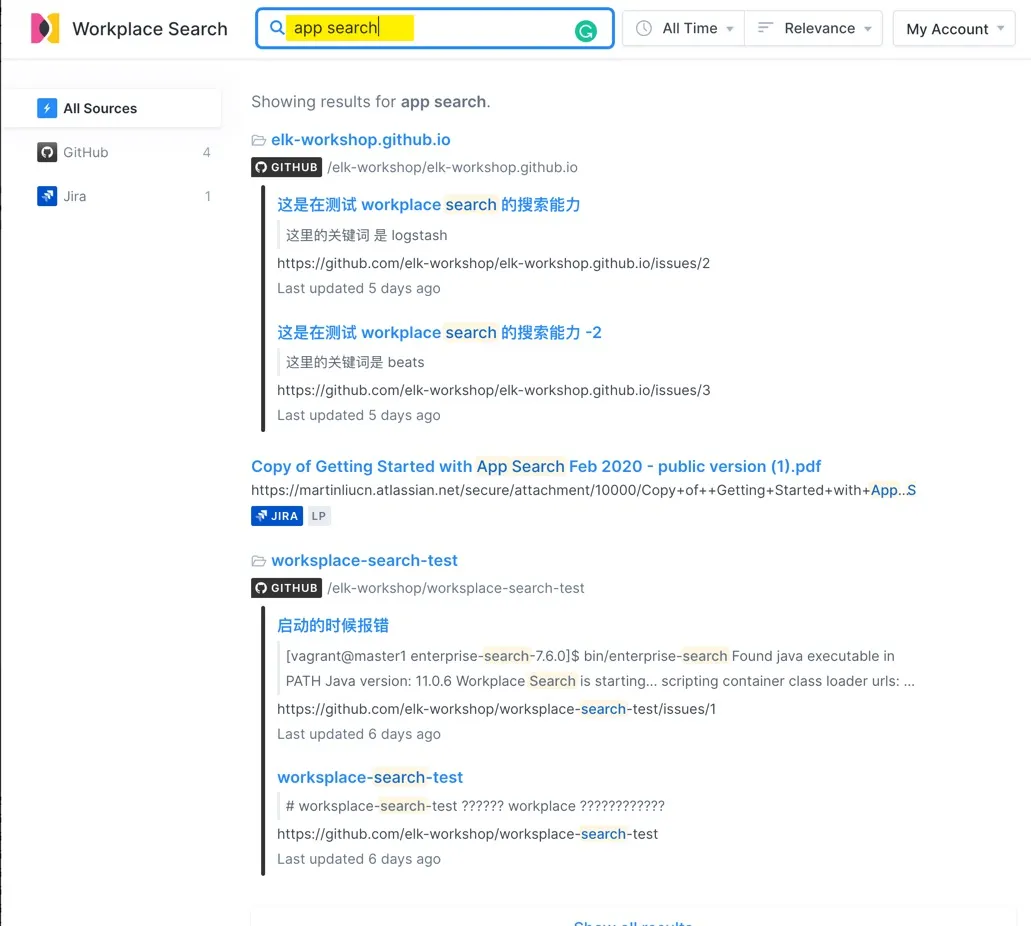
下面这个用户搜索可关键词 app search,从这个结果中可以看出,即使是在 GitHub 中的一半匹配(并无完整的 app search 这个词组出现在任何文档里)搜索结果的排名都比 Jira 中的完全命中的排名高。
测试总结
到目前为止,本文展示了一部分 Elastic Workplace Search 的基础功能。以及一些假象的搜索和配置场景,相信对此感兴趣的读者参考本文,也可以在 1 天之内完全实现以上所有的测试场景,从而为正确评估这个产品打下一个基础。
如果,想进一步集成自己的资料库的话,可以参考自定义 API 的相关文档,开发自定义的数据源。这就是一个功能齐全的搜索平台,它可以非常方便的集成任何公司的环境中,并且实现集中统一搜索平台的效果。
DevOps核心能力建设
如果你也是 DevOps 的实践者,如果你看过我之前写的关于 DevOps 状态调查报告和能力成长模型的相关文章,你可能对下图也有印象。
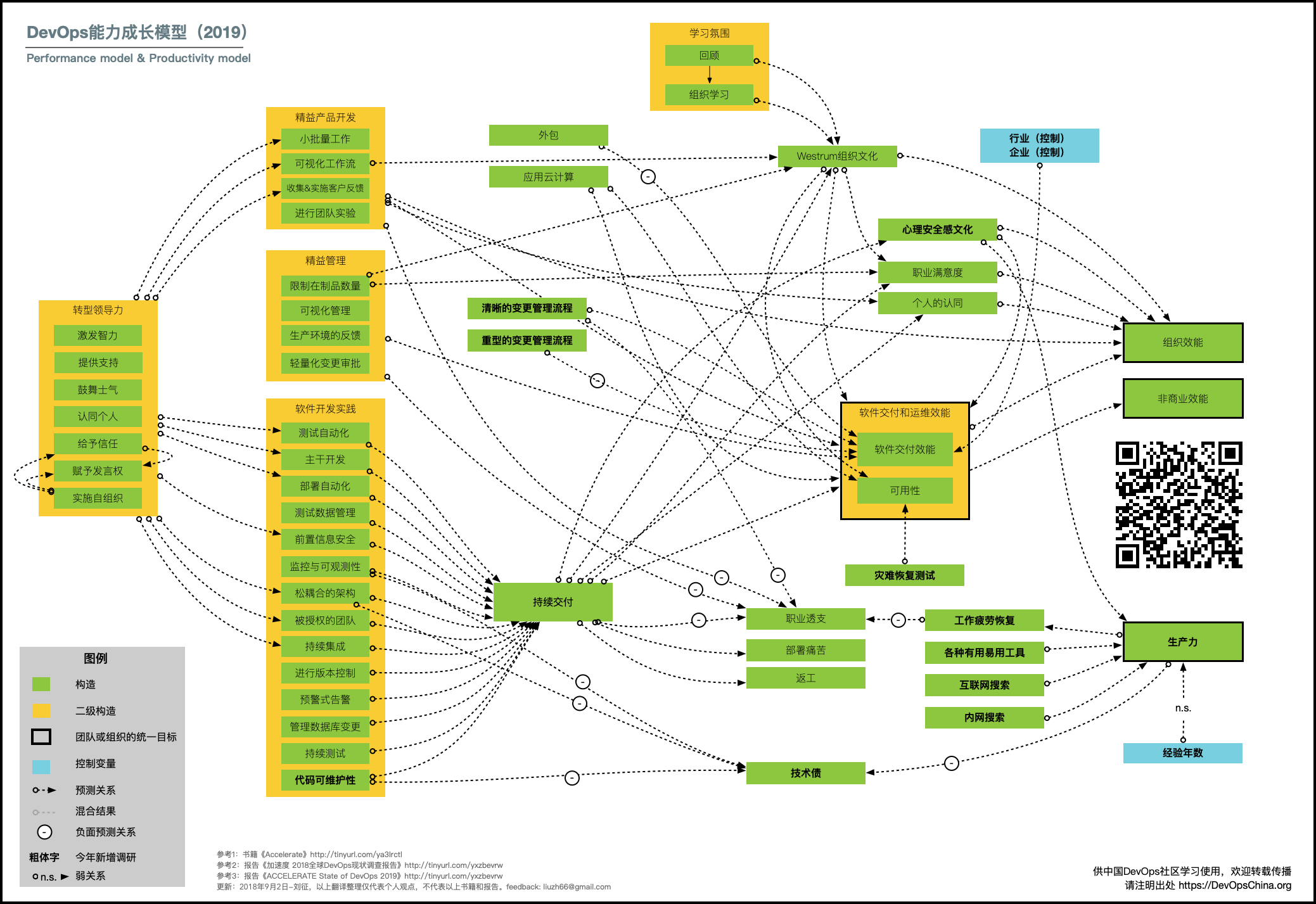
这是 DORA 出的最新版本的 DevOps 能力成长模型,在 2019 年的DevOps 能力调查中,增加了对生产力工具的调查,该模型中所关注的三种生产力能力工具包括:
- 各种有用易用的工具
- 互联网搜索
- 内网搜索
在这个部分有两项生产力影响因素能力是关于搜索的。在我国的很多工作环境中,特别是开发相关的工作,无 Internet 环境的纯内网是很普遍的。而内网上的 Atlassian 相关产品,微软相关产品又是最多用的;不同业务部门或者团队拥有自建的 Jira 或者 Confulence 服务器;在团队协作的时候,或者在执行跨部门的项目的时候,项目资料的统一搜索就成了问题。类似的需求和现象不胜枚举,希望本文介绍的 Elastic Workplace Search 统一搜索平台可以成为你的帮手,为你填补 DevOps 能力成长模型中关于 内网搜索 的这一项空白。当然,这个平台所支持的外网 SaaS 服务也是很多的,可以综合使用。