概述
使用 Elastic Stack 的各种 Beats 模块可以彻底的终结在服务器上手工捞日志查指标的扭曲实践。利用腾讯云提供的 Elasticsearch 服务,可以轻松搞定大规模云环境的运维。本文一次性的帮你梳理清楚了,必备的基础操作,确保你能用 Elastic Stack 安全、稳定和扩展的持续监控你的生产环境。
创建 ES 集群
登录腾讯云服务控制台,查询并进入 Elasticsearc 服务,点击新建按钮,创建 Elasticsearch 集群。如下图所示。
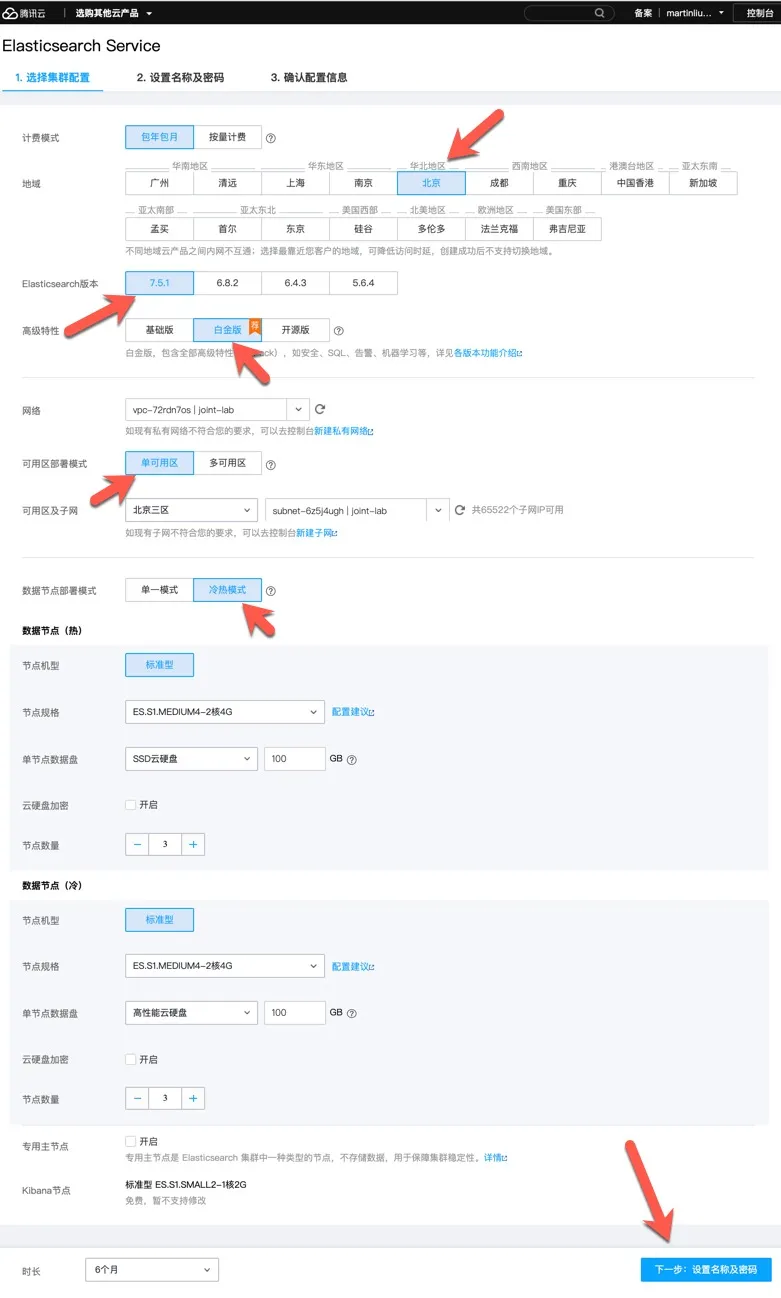
集群配置说明:
本实例其它参数保持默认,可以根据实际业务需求修改这些参数。
点击下一步后,设置 Elasticsearch 集群的超级用户名和密码。
在几分钟之后这个集群就成功创建了。查看下面这些基础的配置。
这样我们就有了一个安全、可扩展和性能足够的 ES 后台服务。
创建 Beats 写入角色和用户
登录 Kibana ,点击角色和用户管理,创建用于 Beast 配置文件的‘只写’权限用户。
- 创建 beats-writer 角色
- 创建 beats-writer 用户,该用户只赋予beats-writer角色,自定义一个安全的复杂密码。
Beats-write 角色设置如下图所示:
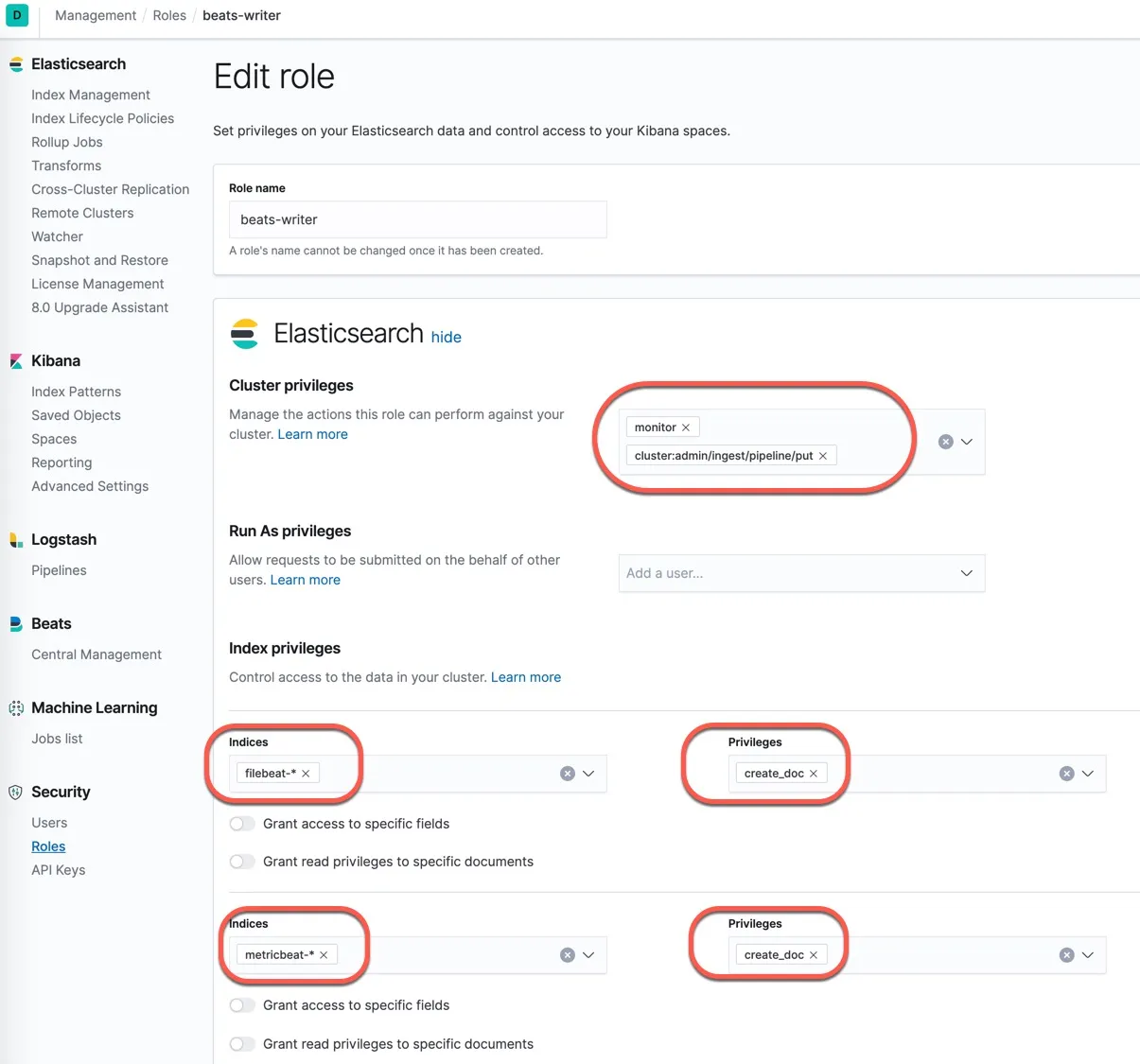
这个用户会用到后面的所有 Beats 配置文件中,用最小化权限用户极大的降低了数据泄露的风险。
Beats 初始化配置
登录准备好的一个 Linux 服务器,在这台机器上做 Beats 相关的初始化工作;也就是要执行一些列的 setup 命令;这些命令的作用是:
- 在 ES 后台加载索引模板,以及索引的 ILM 策略。
- 加载 Kibana 相关的对象和可视化仪表板。
注意这是一次性的工作,在一个虚拟机上,只需要成功执行一次。
SSH 登录到准备的 Linux 服务器上,首先需要安装相关 beats 的 rpm 安装包,安装命令在这里忽略,否则无法执行这些命令。 安装好 filebeat 和 metricbeat 的rpm 包后, 执行下面参考命令。
1
2
3
4
5
6
7
8
9
10
11
12
13
|
filebeat setup -e \
-E output.logstash.enabled=false \
-E output.elasticsearch.hosts=['192.168.0.43:9200'] \
-E output.elasticsearch.username=elastic \
-E output.elasticsearch.password=YourPassWord \
-E setup.kibana.host=es-ot7wei87.internal.kibana.tencentelasticsearch.com:5601
metricbeat setup -e \
-E output.elasticsearch.hosts=['192.168.0.43:9200'] \
-E output.elasticsearch.username=elastic \
-E output.elasticsearch.password=YourPassWord \
-E setup.kibana.host=es-ot7wei87.internal.kibana.tencentelasticsearch.com:5601
|
运行以上命令的时候 Beats 处于默认安装的状态,这些命令行参数是必要的查收,有了这些参数 beats 会忽略默认的配置文件。
以上命令根据需求,如果需要使用到其它的 Beats,请使用相关的 setup 命令。其中的 es 和 kibana 相关信息需求参考上一步创建的 es 集群信息。
以上所有命令成功之后,登录 Kibana 界面,点击 Dashboard 菜单,这里应该已经加载了很多仪表板。目前为止 Elastic Stack 后台就初始化成功了。
在节点上正式部署 Beats
参考和修改安装脚本,一键式安装和配置 Beats
1
2
3
| git clone https://github.com/martinliu/elastic-stack-lab.git
cd tencent
sh add-agent.sh
|
成功执行完以上脚本后,相关的 beats 服务应是正常运行的状态。执行完这个命令之后,在 Linux 服务器上使用检查服务是否正常运行 sudo systemctl status filebeat ;使用这个命令应该可以看到filebeat 服务都是正常运行的。
这个脚本所使用的配置文件中的要点:
- 删除了所有和数据摄入无关的配置(例如 es 和 kibana 的配置和初始化等)
- 加入了最小化的必要的最佳实践参数集合
- 建议根据需求增加 beats 相关的模块
- 根据需求加入必要的 Beat 配置参数
实例配置文件如。
filebeat.yml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| #=========================== Filebeat inputs =============================
filebeat.inputs:
- type: log
enabled: false
paths:
- /var/log/*.log
#============================= Filebeat modules ===============================
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: true
reload.period: 60s
#-------------------------- Elasticsearch output ------------------------------
output.elasticsearch:
hosts: ["${INT_ES_SRV}"]
password: ${BEATS_WRITER_PW}
username: ${BEATS_WRITER_USERNAME}
#================================ Processors =====================================
processors:
- add_host_metadata:
netinfo.enabled: true
cache.ttl: 5m
- add_cloud_metadata: ~
- add_docker_metadata: ~
- add_kubernetes_metadata: ~
- add_fields:
target: ''
fields:
service.name: 'Joint Lab'
service.id: 'es-qq'
#==================== Best Practice Configuration ==========================
setup.ilm.check_exists: false
logging.level: error
queue.spool: ~
monitoring:
enabled: true
|
metricbeat.yml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| # =========================== Modules configuration ============================
metricbeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: true
reload.period: 10s
#-------------------------- Elasticsearch output ------------------------------
output.elasticsearch:
hosts: ["${INT_ES_SRV}"]
password: ${BEATS_WRITER_PW}
username: ${BEATS_WRITER_USERNAME}
#================================ Processors =====================================
processors:
- add_host_metadata:
netinfo.enabled: true
cache.ttl: 5m
- add_cloud_metadata: ~
- add_docker_metadata: ~
- add_kubernetes_metadata: ~
- add_fields:
target: ''
fields:
service.name: 'Joint Lab'
service.id: 'es-qq'
#==================== Best Practice Configuration ==========================
setup.ilm.check_exists: false
logging.level: error
queue.spool: ~
monitoring:
enabled: true
|
以上配置文件使用了这些通用最佳实践配置参数。
- 使用 ECS 扩展字段,丰富上下文含义
- 启用 beats 端点监控
- 用 keystore 隐藏所有敏感信息
1
2
3
4
5
6
7
8
9
10
11
12
| #禁用索引 ilm 策略检查,避免无用动作
setup.ilm.check_exists: false
#把Beats自身的日志记录调到最低级别降低
logging.level: error
#开启本地默认的端点缓存行为
queue.spool: ~
#启用端点的监控
monitoring:
enabled: true
|
排错方法
filebeat setup 不成功
在任何 beats 首次做 setup 命令的时候,它可能是会在分钟级别成功结束。如果发生失败或者卡顿的情况,可以等一下,等更长时间看看。不成功的话,需要反复执行,排查 es 和 kibana 服务是否能正常工作。知道陈功了,才能进行下一步的安装工作。
配置文件错误导致的服务不能启动
由于上面的定制化配置文件也可能出现错误,特别是在首次部署这个配置文件的时候,可以先把日志级别 error 哪一行注释掉,把启动服务那两行也注释掉。
然后在命令行执行 filebeat -e 查看整个 feilebeat 的启动过程,这个命令会读取定制化的配置文件,然后开始连接后台 es 服务,然后进入正常数据传送的状态。这个过程中如果有任何配置错误,也可以直观的看到相关信息,直到调整到正常的状态。
以上过程的调整好了以后,一定要通过 git 版本管理起来,然后可以放心的在其它节点上执行 beast 的一键式部署工作。
总结
以上是在 Beats 部署相关基础最佳实践,也就是说在生产环境中 ES 后台和 beats 的搭配,以及本文所涉及的内容都是基线配置。建议根据自己的需求做更多的调优,这里使用 shell 脚本的方式部署 beats 和相关的配置,shell 脚本适合用于演示原理,建议替换成你所熟悉的自动化运维工具,例如 ansible 等工具。从而保证更大规模的自动化部署和维护。
本相关的配置文件和脚本位于:https://github.com/martinliu/elastic-stack-lab.git
